- Python Web Scraping Cookbook
- Michael Heydt
- 257字
- 2021-06-30 18:43:57
How it works...
We will dive into details of both Requests and Beautiful Soup in the next chapter, but for now let's just summarize a few key points about how this works. The following important points about Requests:
- Requests is used to execute HTTP requests. We used it to make a GET verb request of the URL for the events page.
- The Requests object holds the results of the request. This is not only the page content, but also many other items about the result such as HTTP status codes and headers.
- Requests is used only to get the page, it does not do an parsing.
We use Beautiful Soup to do the parsing of the HTML and also the finding of content within the HTML.
To understand how this worked, the content of the page has the following HTML to start the Upcoming Events section:
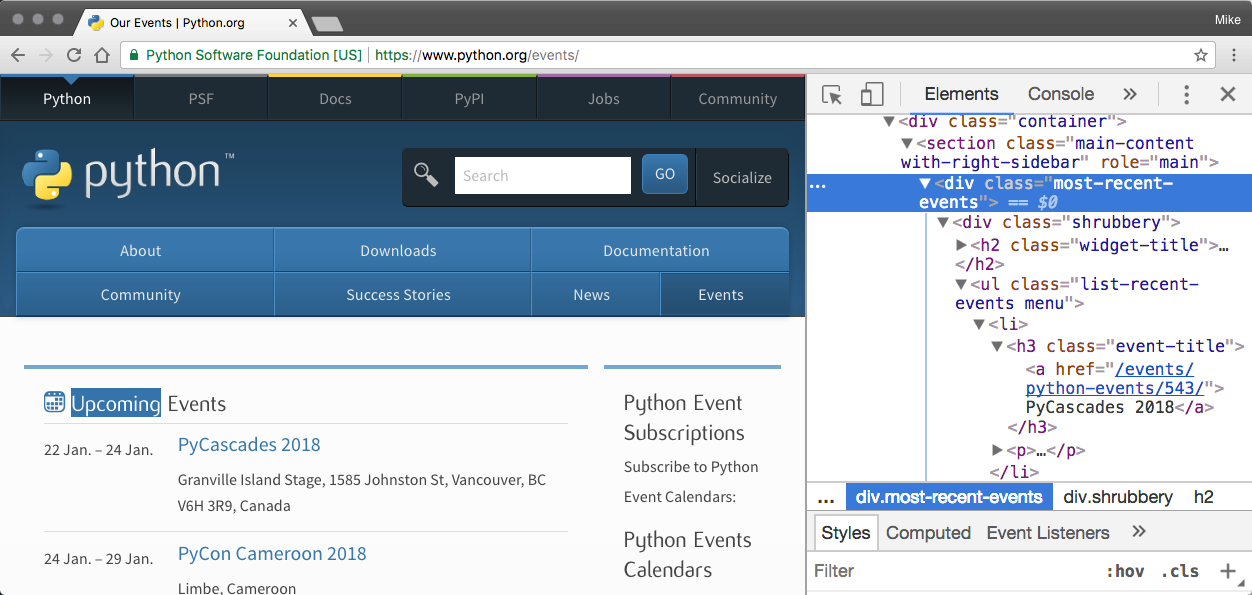
We used the power of Beautiful Soup to:
- Find the <ul> element representing the section, which is found by looking for a <ul> with the a class attribute that has a value of list-recent-events.
- From that object, we find all the <li> elements.
Each of these <li> tags represent a different event. We iterate over each of those making a dictionary from the event data found in child HTML tags:
- The name is extracted from the <a> tag that is a child of the <h3> tag
- The location is the text content of the <span> with a class of event-location
- And the time is extracted from the datetime attribute of the <time> tag.