- Deep Learning with PyTorch
- Vishnu Subramanian
- 489字
- 2021-06-24 19:16:27
Layers – fundamental blocks of neural networks
Throughout the rest of the chapter, we will come across different types of layers. To begin, let's try to understand one of the most important layers, the linear layer, which does exactly what our previous network architecture does. The linear layer applies a linear transformation:
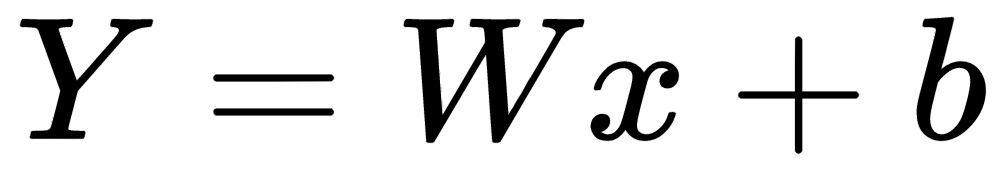
What makes it powerful is that fact that the entire function that we wrote in the previous chapter can be written in a single line of code, as follows:
from torch.nn import Linear
myLayer = Linear(in_features=10,out_features=5,bias=True)
The myLayer in the preceding code will accept a tensor of size 10 and outputs a tensor of size 5 after applying linear transformation. Let's look at a simple example of how to do that:
inp = Variable(torch.randn(1,10))
myLayer = Linear(in_features=10,out_features=5,bias=True)
myLayer(inp)
We can access the trainable parameters of the layer using the weights and bias attributes:
myLayer.weight
Output :
Parameter containing:
-0.2386 0.0828 0.2904 0.3133 0.2037 0.1858 -0.2642 0.2862 0.2874 0.1141
0.0512 -0.2286 -0.1717 0.0554 0.1766 -0.0517 0.3112 0.0980 -0.2364 -0.0442
0.0776 -0.2169 0.0183 -0.0384 0.0606 0.2890 -0.0068 0.2344 0.2711 -0.3039
0.1055 0.0224 0.2044 0.0782 0.0790 0.2744 -0.1785 -0.1681 -0.0681 0.3141
0.2715 0.2606 -0.0362 0.0113 0.1299 -0.1112 -0.1652 0.2276 0.3082 -0.2745
[torch.FloatTensor of size 5x10]
myLayer.bias
Output :
Parameter containing:
-0.2646
-0.2232
0.2444
0.2177
0.0897
[torch.FloatTensor of size 5
Linear layers are called by different names, such as dense or fully connected layers across different frameworks. Deep learning architectures used for solving real-world use cases generally contain more than one layer. In PyTorch, we can do it in multiple ways, shown as follows.
One simple approach is passing the output of one layer to another layer:
myLayer1 = Linear(10,5)
myLayer2 = Linear(5,2)
myLayer2(myLayer1(inp))
Each layer will have its own learnable parameters. The idea behind using multiple layers is that each layer will learn some kind of pattern that the later layers will build on. There is a problem in adding just linear layers together, as they fail to learn anything new beyond a simple representation of a linear layer. Let's see through a simple example of why it does not make sense to stack multiple linear layers together.
Let's say we have two linear layers with the following weights:

The preceding architecture with two different layers can be simply represented as a single layer with a different layer. Hence, just stacking multiple linear layers will not help our algorithms to learn anything new. Sometimes, this can be unclear, so we can visualize the architecture with the following mathematical formulas:
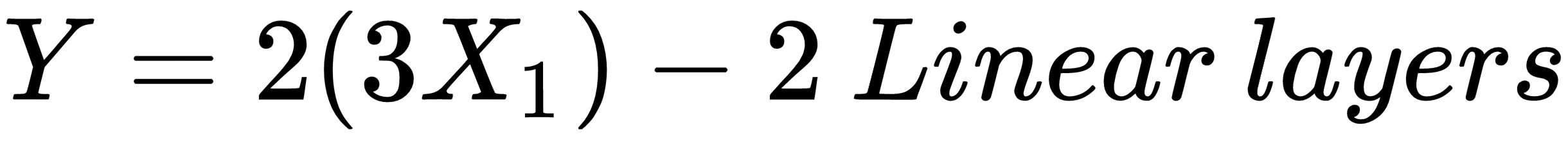

To solve this problem, we have different non-linearity functions that help in learning different relationships, rather than only focusing on linear relationships.
There are many different non-linear functions available in deep learning. PyTorch provides these non-linear functionalities as layers and we will be able to use them the same way we used the linear layer.
Some of the popular non-linear functions are as follows:
- Sigmoid
- Tanh
- ReLU
- Leaky ReLU
- Learning SQL Server Reporting Services 2012
- Learning Cocos2d-x Game Development
- INSTANT Wijmo Widgets How-to
- 深入淺出SSD:固態存儲核心技術、原理與實戰
- 電腦組裝、維護、維修全能一本通(全彩版)
- 電腦常見故障現場處理
- Artificial Intelligence Business:How you can profit from AI
- Large Scale Machine Learning with Python
- CC2530單片機技術與應用
- Machine Learning Solutions
- Machine Learning with Go Quick Start Guide
- 固態存儲:原理、架構與數據安全
- Spring Cloud微服務和分布式系統實踐
- Managing Data and Media in Microsoft Silverlight 4:A mashup of chapters from Packt's bestselling Silverlight books
- 微控制器的應用