- Deep Learning with PyTorch
- Vishnu Subramanian
- 391字
- 2021-06-24 19:16:22
Our first neural network
We present our first neural network, which learns how to map training examples (input array) to targets (output array). Let's assume that we work for one of the largest online companies, Wondermovies, which serves videos on demand. Our training dataset contains a feature that represents the average hours spent by users watching movies on the platform and we would like to predict how much time each user would spend on the platform in the coming week. It's just an imaginary use case, don't think too much about it. Some of the high-level activities for building such a solution are as follows:
- Data preparation: The get_data function prepares the tensors (arrays) containing input and output data
- Creating learnable parameters: The get_weights function provides us with tensors containing random values that we will optimize to solve our problem
- Network model: The simple_network function produces the output for the input data, applying a linear rule, multiplying weights with input data, and adding the bias term (y = Wx+b)
- Loss: The loss_fn function provides information about how good the model is
- Optimizer: The optimize function helps us in adjusting random weights created initially to help the model calculate target values more accurately
If you are new to machine learning, do not worry, as we will understand exactly what each function does by the end of the chapter. The following functions abstract away PyTorch code to make it easier for us to understand. We will dive deep into each of these functionalities in detail. The aforementioned high level activities are common for most machine learning and deep learning problems. Later chapters in the book discuss techniques that can be used to improve each function to build useful applications.
Lets consider following linear regression equation for our neural network:
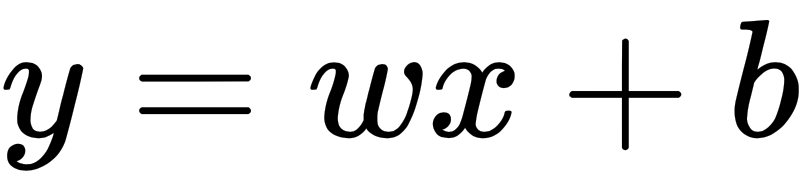
Let's write our first neural network in PyTorch:
x,y = get_data() # x - represents training data,y - represents target variables
w,b = get_weights() # w,b - Learnable parameters
for i in range(500):
y_pred = simple_network(x) # function which computes wx + b
loss = loss_fn(y,y_pred) # calculates sum of the squared differences of y and y_pred
if i % 50 == 0:
print(loss)
optimize(learning_rate) # Adjust w,b to minimize the loss
By the end of this chapter, you will have an idea of what is happening inside each function.
- 零點起飛學Xilinx FPG
- Intel FPGA/CPLD設計(基礎篇)
- 用“芯”探核:龍芯派開發實戰
- 顯卡維修知識精解
- 基于Proteus和Keil的C51程序設計項目教程(第2版):理論、仿真、實踐相融合
- 電腦組裝、維護、維修全能一本通(全彩版)
- 硬件產品經理手冊:手把手構建智能硬件產品
- 3ds Max Speed Modeling for 3D Artists
- 平衡掌控者:游戲數值經濟設計
- Svelte 3 Up and Running
- 微軟互聯網信息服務(IIS)最佳實踐 (微軟技術開發者叢書)
- 超大流量分布式系統架構解決方案:人人都是架構師2.0
- Hands-On Artificial Intelligence for Banking
- Spring Cloud微服務和分布式系統實踐
- Spring Cloud實戰