- Big Data Analytics with Hadoop 3
- Sridhar Alla
- 750字
- 2021-06-25 21:26:17
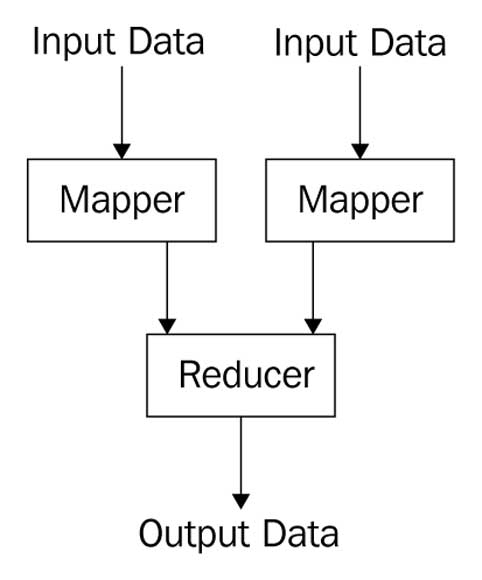
Multiple mappers reducer job
Multiple mappers reducer jobs are used in join use cases. In this design pattern, our input is taken from multiple input files to yield joined/aggregated output:

Now let's look at a complete example of a single mapper reducer job. For this, we will simply try to output the cityID and average temperature from the temperature.csv file seen earlier.
The following is the code:
package io.somethinglikethis;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MultipleMappersReducer
{
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "City Temperature Job");
job.setMapperClass(TemperatureMapper.class);
MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, CityMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, TemperatureMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(TemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[2]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/*
Id,City
1,Boston
2,New York
*/
private static class CityMapper
extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String txt = value.toString();
String[] tokens = txt.split(",");
String id = tokens[0].trim();
String name = tokens[1].trim();
if (name.compareTo("City") != 0)
context.write(new Text(id), new Text(name));
}
}
/*
Date,Id,Temperature
2018-01-01,1,21
2018-01-01,2,22
*/
private static class TemperatureMapper
extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String txt = value.toString();
String[] tokens = txt.split(",");
String date = tokens[0];
String id = tokens[1].trim();
String temperature = tokens[2].trim();
if (temperature.compareTo("Temperature") != 0)
context.write(new Text(id), new Text(temperature));
}
}
private static class TemperatureReducer
extends Reducer<Text, Text, Text, IntWritable> {
private IntWritable result = new IntWritable();
private Text cityName = new Text("Unknown");
public void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
int n = 0;
cityName = new Text("city-"+key.toString());
for (Text val : values) {
String strVal = val.toString();
if (strVal.length() <=3)
{
sum += Integer.parseInt(strVal);
n +=1;
} else {
cityName = new Text(strVal);
}
}
if (n==0) n = 1;
result.set(sum/n);
context.write(cityName, result);
}
}
}
Now, run the command, as shown in the following code:
hadoop jar target/uber-mapreduce-1.0-SNAPSHOT.jar io.somethinglikethis.MultipleMappersReducer /user/normal/cities.csv /user/normal/temperatures.csv /user/normal/output/MultipleMappersReducer
The job will run and you should be able to see output as shown in the following output counters:
Map-Reduce Framework -- mapper for temperature.csv
Map input records=28
Map output records=27
Map output bytes=135
Map output materialized bytes=195
Input split bytes=286
Combine input records=0
Spilled Records=27
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=430964736
Map-Reduce Framework. -- mapper for cities.csv
Map input records=7
Map output records=6
Map output bytes=73
Map output materialized bytes=91
Input split bytes=273
Combine input records=0
Spilled Records=6
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=10
Total committed heap usage (bytes)=657457152
Map-Reduce Framework -- output average temperature per city name
Map input records=35
Map output records=33
Map output bytes=208
Map output materialized bytes=286
Input split bytes=559
Combine input records=0
Combine output records=0
Reduce input groups=7
Reduce shuffle bytes=286
Reduce input records=33
Reduce output records=7
Spilled Records=66
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=10
Total committed heap usage (bytes)=1745879040
This shows that 27 records were output from one Mapper, six records were output from Mapper2 and seven records were output by the reducer. You will be able to check this using the HDFS browser, simply by using http://localhost:9870 and jumping into the output directory shown under /user/normal/output, as shown in the following screenshot:
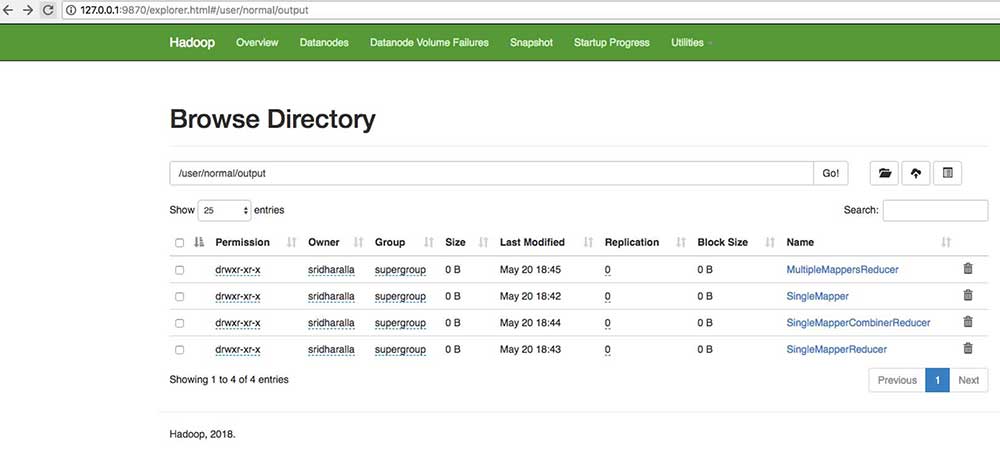
Figure: Check output in output directory
Now find the MultipleMappersReducer folder go into the directory, and then drill down as in the SingleMapper section; then, using the head/tail option in the preceding screenshot, you can view the content of the file, as shown in the following screenshot:
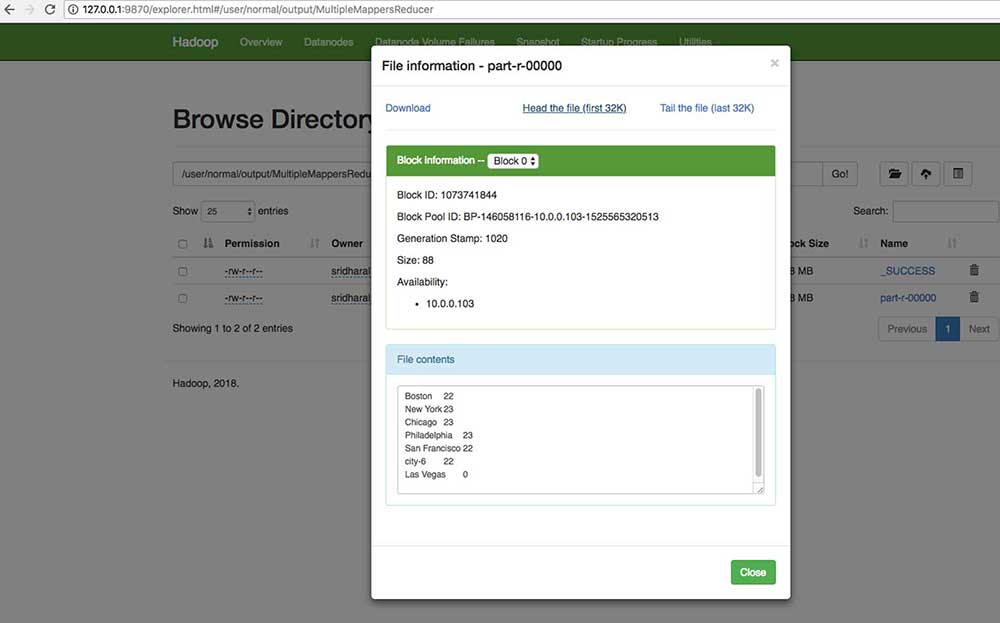
Figure: Content of the file
This shows the output of the MultipleMappersReducer job as the cityName and average temperature per city. If a cityID does not have corresponding temperature records in temperature.csv, the average is shown as 0. Similarly, if a cityID does not have a name in cities.csv, then the city name is shown as city-N.
You can also use the command line to view the contents of output hdfs dfs -cat /user/normal/output/MultipleMappersReducer/part-r-00000.
The output file contents are shown in the following code:
Boston 22
New York 23
Chicago 23
Philadelphia 23
San Francisco 22
city-6 22 //city ID 6 has no name in cities.csv only temperature measurements
Las Vegas 0 // city of Las vegas has no temperature measurements in temperature.csv
This concludes the MultipleMappersReducer job execution, and the output is as expected.
- 程序設計語言與編譯
- 最簡數據挖掘
- VB語言程序設計
- Cloudera Administration Handbook
- Java Web整合開發全程指南
- Splunk Operational Intelligence Cookbook
- 運動控制系統應用與實踐
- 單片機C語言應用100例
- Building a BeagleBone Black Super Cluster
- 電腦上網輕松入門
- Mastering Predictive Analytics with scikit:learn and TensorFlow
- 大數據:引爆新的價值點
- Cisco UCS Cookbook
- Learning OpenShift
- Architectural Patterns