- Intelligent Projects Using Python
- Santanu Pattanayak
- 436字
- 2021-07-02 14:10:50
Network architecture
We will now experiment with the pre-trained ResNet50, InceptionV3, and VGG16 networks, and find out which one gives the best results. Each of the pre-trained models' weights are based on ImageNet. I have provided the links to the original papers for the ResNet, InceptionV3, and VGG16 architectures, for reference. Readers are advised to go over these papers, to get an in-depth understanding of these architectures and the subtle differences between them.
The VGG paper link is as follows:
- Title: Very Deep Convolutional Networks for Large-Scale Image Recognition
- Link: https://arxiv.org/abs/1409.1556
The ResNet paper link is as follows:
- Title: Deep Residual Learning for Image Recognition
- Link: https://arxiv.org/abs/1512.03385
The InceptionV3 paper link is as follows:
- Title: Rethinking the Inception Architecture for Computer Vision
- Link: https://arxiv.org/abs/1512.00567
To explain in brief, VGG16 is a 16-layered CNN that uses 3 x 3 filters and 2 x 2 receptive fields for convolution. The activation functions used throughout the network are all ReLUs. The VGG architecture, developed by Simonyan and Zisserman, was the runner up in the ILSVRC 2014 competition. The VGG16 network gained a lot of popularity due to its simplicity, and it is the most popular network for extracting features from images.
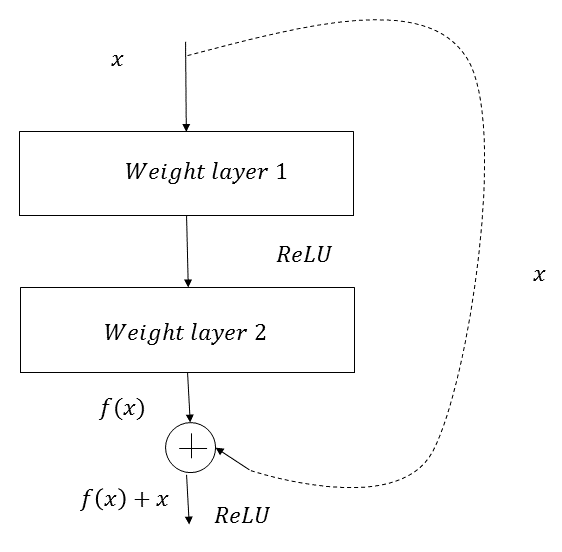
ResNet50 is a deep CNN that implements the idea of residual block, quite different from that of the VGG16 network. After a series of convolution-activation-pooling operations, the input of the block is again fed back to the output. The ResNet architecture was developed by Kaiming He, et al., and although it has 152 layers, it is less complex than the VGG network. This architecture won the ILSVRC 2015 competition by achieving a top five error rate of 3.57%, which is better than the human-level performance on this competition dataset. The top five error rate is computed by checking whether the target is in the five class predictions with the highest probability. In principle, the ResNet network tries to learn the residual mapping, as opposed to directly mapping from the output to the input, as you can see in the following residual block diagram:
InceptionV3 is the state-of-the-art CNN from Google. Instead of using fixed-sized convolutional filters at each layer, the InceptionV3 architecture uses filters of different sizes to extract features at different levels of granularity. The convolution block of an InceptionV3 layer is illustrated in the following diagram:
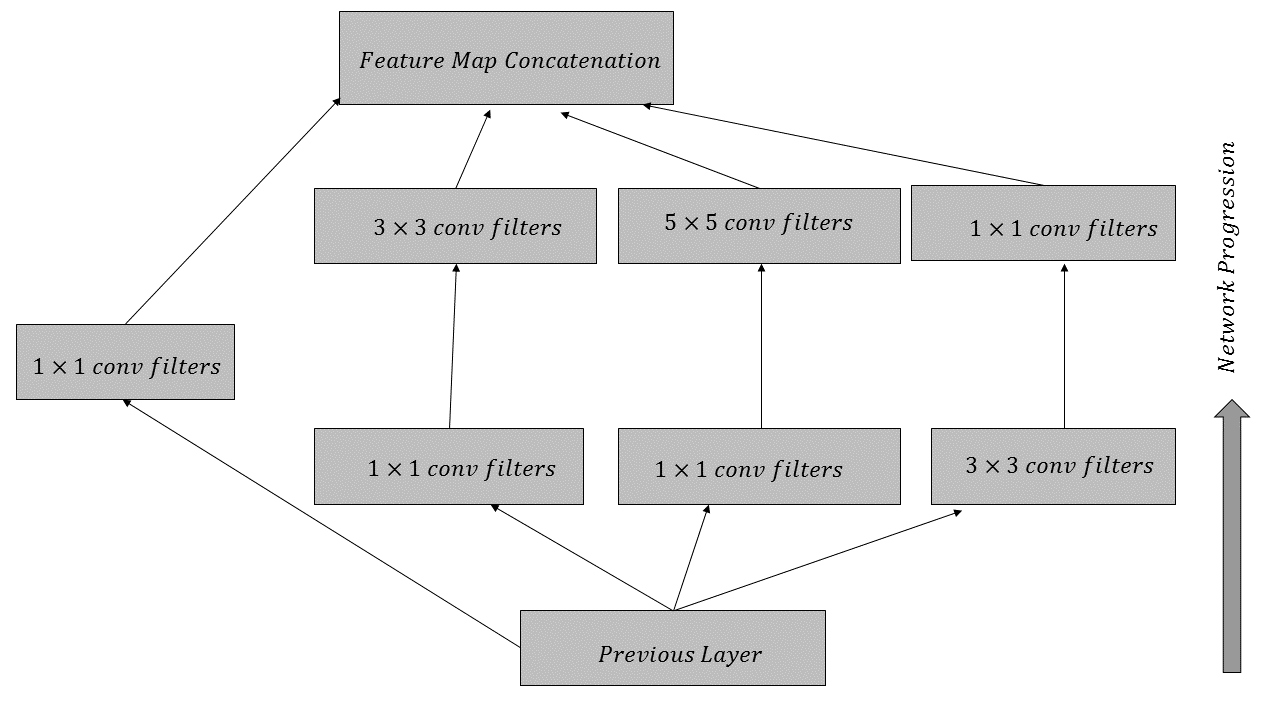
Inception V1 (GoogleNet) was the winner of the ILSVRC 2014 competition. Its top 5% error rate was very close to human-level performance, at 6.67%.