- Intelligent Projects Using Python
- Santanu Pattanayak
- 524字
- 2021-07-02 14:10:46
Restricted Boltzmann machines
Restricted Boltzmann machines (RBMs) are an unsupervised class of machine learning algorithms that learn the internal representation of data. An RBM has a visible layer, v ∈ Rm, and a hidden layer, h ∈ Rn. RBMs learn to present the input in the visible layer as a low-dimensional representation in the hidden layer. All of the hidden layer units are conditionally independent, given the visible layer input. Similarly, all of the visible layers are conditionally independent, given the hidden layer input. This allows the RBM to sample the output of the visible units independently, given the hidden layer input, and vice versa.
The following diagram illustrates the architecture of an RBM:
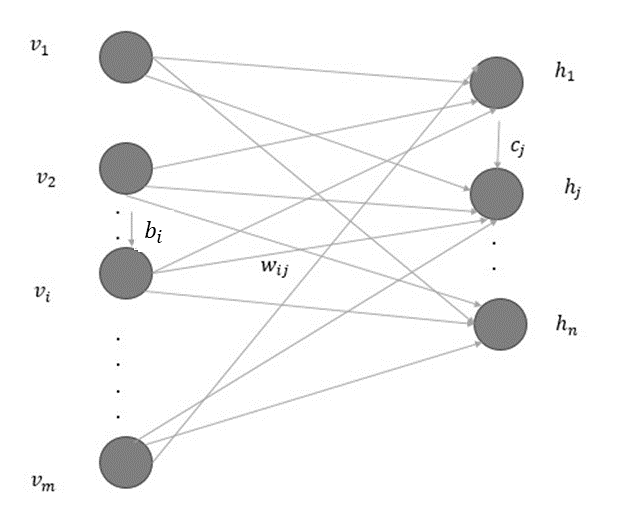
The weight, wij ∈ W, connects the visible unit, i, to the hidden unit, j, where W ∈ Rm x n is the set of all such weights, from visible units to hidden units. The biases in the visible units are represented by bi ∈ b, whereas the biases in the hidden units are represented by cj ∈ c.
Inspired by ideas from the Boltzmann distribution in statistical physics, the joint distribution of a visible layer vector, v, and a hidden layer vector, h, is made proportional to the exponential of the negative energy of the configuration:
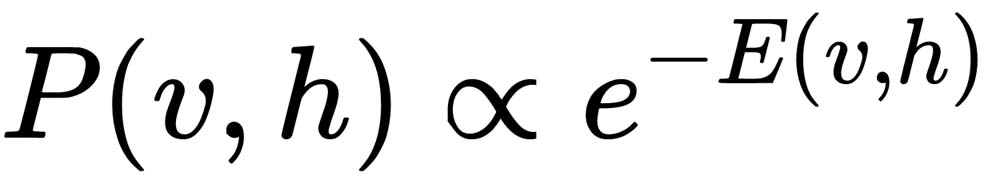 (1)
(1)
The energy of a configuration is given by the following:
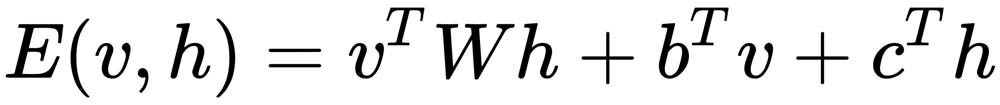 (2)
(2)
The probability of the hidden unit, j, given the visible input vector, v, can be represented as follows:
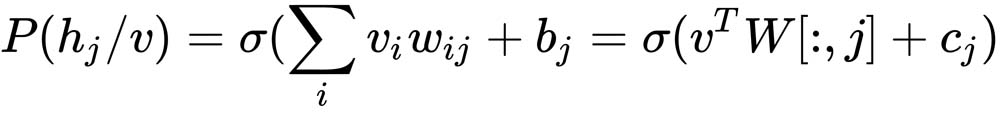 (2)
(2)
Similarly, the probability of the visible unit, i, given the hidden input vector, h, is given by the following:
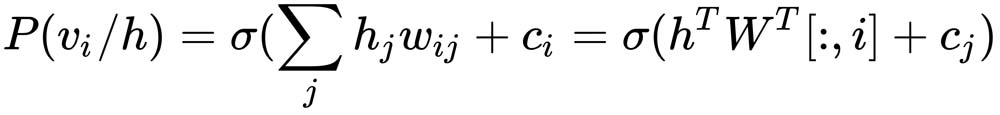 (3)
(3)
So, once we have learned the weights and biases of the RBM through training, the visible representation can be sampled, given the hidden state, while the hidden state can be sampled, given the visible state.
Similar to principal component analysis (PCA), RBMs are a way to represent data in one dimension, provided by the visible layer, v, into a different dimension, provided by the hidden layer, h. When the dimensionality of the hidden layer is less than that of the visible layer, the RBMs perform the task of dimensionality reduction. RBMs are generally trained on binary data.
RBMs are trained by maximizing the likelihood of the training data. In each iteration of gradient descent of the cost function with respect to the weights and biases, sampling comes into the picture, which makes the training process expensive and somewhat computationally intractable. A smart method of sampling, called contrastive divergence—which uses Gibbs sampling—is used to train the RBMs.
We will be using RBMs to build recommender systems in Chapter 6, The Intelligent Recommender System.
- Intel FPGA/CPLD設(shè)計(基礎(chǔ)篇)
- 24小時學(xué)會電腦組裝與維護
- Arduino入門基礎(chǔ)教程
- 觸摸屏實用技術(shù)與工程應(yīng)用
- Cortex-M3 + μC/OS-II嵌入式系統(tǒng)開發(fā)入門與應(yīng)用
- 新型電腦主板關(guān)鍵電路維修圖冊
- 電腦軟硬件維修大全(實例精華版)
- 電腦常見問題與故障排除
- 電腦常見故障現(xiàn)場處理
- VCD、DVD原理與維修
- 計算機組裝維修與外設(shè)配置(高等職業(yè)院校教改示范教材·計算機系列)
- 單片機系統(tǒng)設(shè)計與開發(fā)教程
- STM32自學(xué)筆記
- 單片機原理與技能訓(xùn)練
- 微控制器的應(yīng)用