- Intelligent Projects Using Python
- Santanu Pattanayak
- 169字
- 2021-07-02 14:10:45
Deep Q-learning
In Q-learning, we generally work with a finite set of states and actions; this means that, tables suffice to hold the Q-values and rewards. However, in practical applications, the number of states and applicable actions are mostly infinite, and better Q-function approximators are needed to represent and learn the Q-functions. This is where deep neural networks come to the rescue, since they are universal function approximators. We can represent the Q-function with a neural network that takes the states and actions as input and provides the corresponding Q-values as output. Alternatively, we can train a neural network using only the states, and have the output as Q-values corresponding to all of the actions. Both of these scenarios are illustrated in the following diagram. Since the Q-values are rewards, we are dealing with regression in these networks:
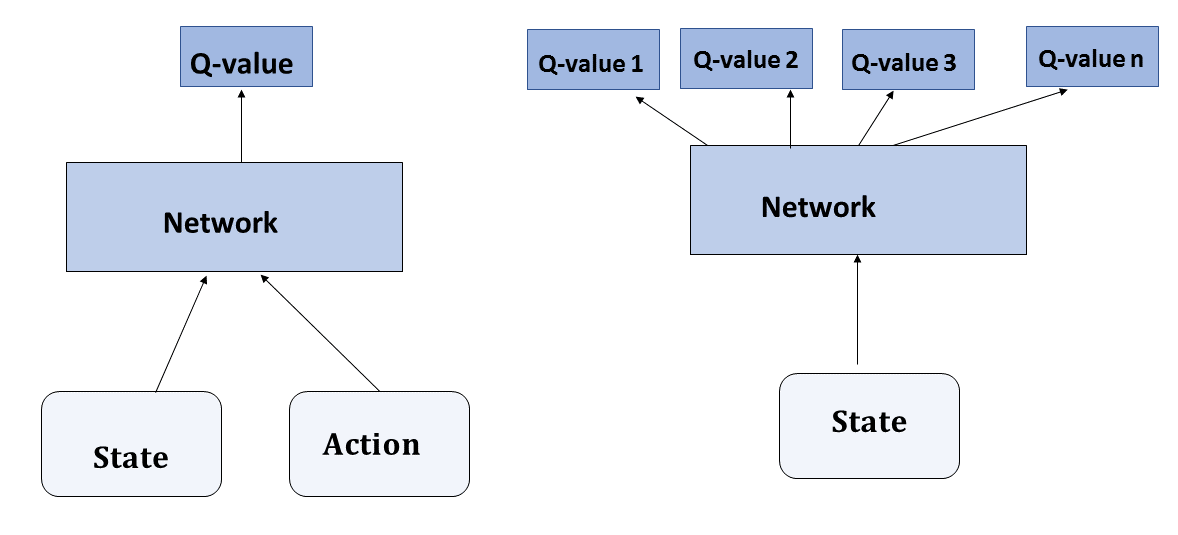
In this book, we will use reinforcement learning to train a race car to drive by itself through deep Q-learning.
- 圖解西門子S7-200系列PLC入門
- 計算機(jī)應(yīng)用與維護(hù)基礎(chǔ)教程
- 精選單片機(jī)設(shè)計與制作30例(第2版)
- 嵌入式系統(tǒng)設(shè)計教程
- 電腦軟硬件維修從入門到精通
- 嵌入式系統(tǒng)中的模擬電路設(shè)計
- CC2530單片機(jī)技術(shù)與應(yīng)用
- 筆記本電腦應(yīng)用技巧
- Intel Edison智能硬件開發(fā)指南:基于Yocto Project
- STM32自學(xué)筆記
- 基于網(wǎng)絡(luò)化教學(xué)的項(xiàng)目化單片機(jī)應(yīng)用技術(shù)
- 筆記本電腦維修技能實(shí)訓(xùn)
- USB應(yīng)用開發(fā)寶典
- 計算機(jī)組成技術(shù)教程
- 微服務(wù)架構(gòu)基礎(chǔ)(Spring Boot+Spring Cloud+Docker)