- Intelligent Projects Using Python
- Santanu Pattanayak
- 243字
- 2021-07-02 14:10:42
Rectified linear unit (ReLU)
The output of a ReLU is linear when the total input to the neuron is greater than zero, and the output is zero when the total input to the neuron is negative. This simple activation function provides nonlinearity to a neural network, and, at the same time, it provides a constant gradient of one with respect to the total input. This constant gradient helps to keep the neural network from developing saturating or vanishing gradient problems, as seen in activation functions, such as sigmoid and tanh activation units. The ReLU function output (as shown in Figure 1.8) can be expressed as follows:
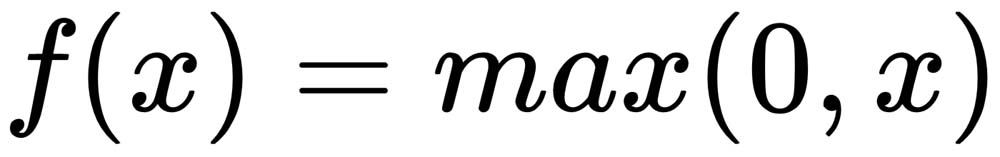
The ReLU activation function can be plotted as follows:
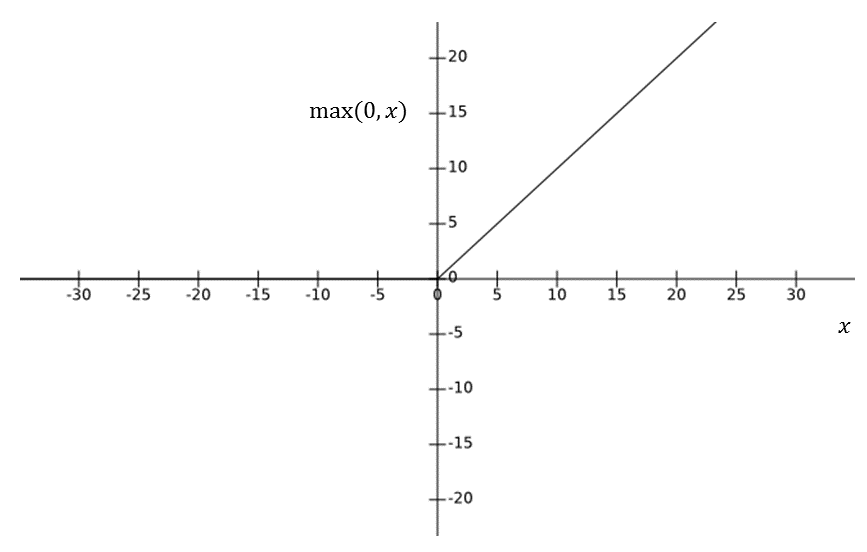
One of the constraints for ReLU is its zero gradients for negative values of input. This may slow down the training, especially at the initial phase. Leaky ReLU activation functions (as shown in Figure 1.9) can be useful in this scenario, where the output and gradients are nonzero, even for negative values of the input. A leaky ReLU output function can be expressed as follows:
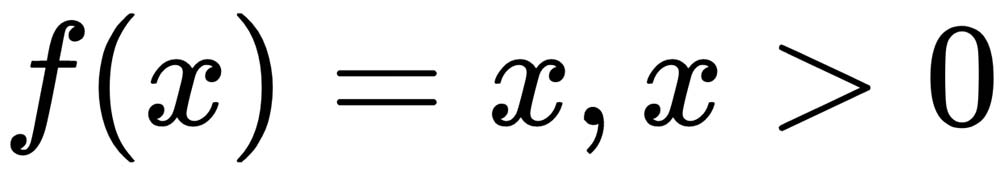
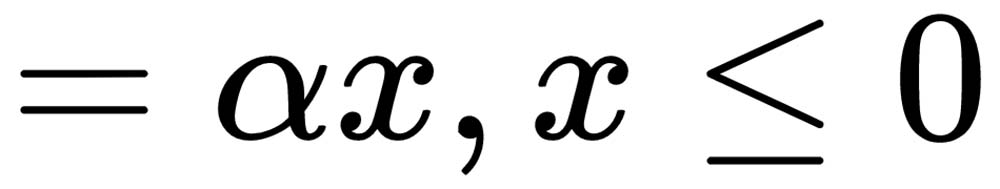
The  parameter is to be provided for leaky ReLU activation functions, whereas for a parametric ReLU,
parameter is to be provided for leaky ReLU activation functions, whereas for a parametric ReLU,  is a parameter that the neural network will learn through training. The following graph shows the output of the leaky ReLU activation function:
is a parameter that the neural network will learn through training. The following graph shows the output of the leaky ReLU activation function:
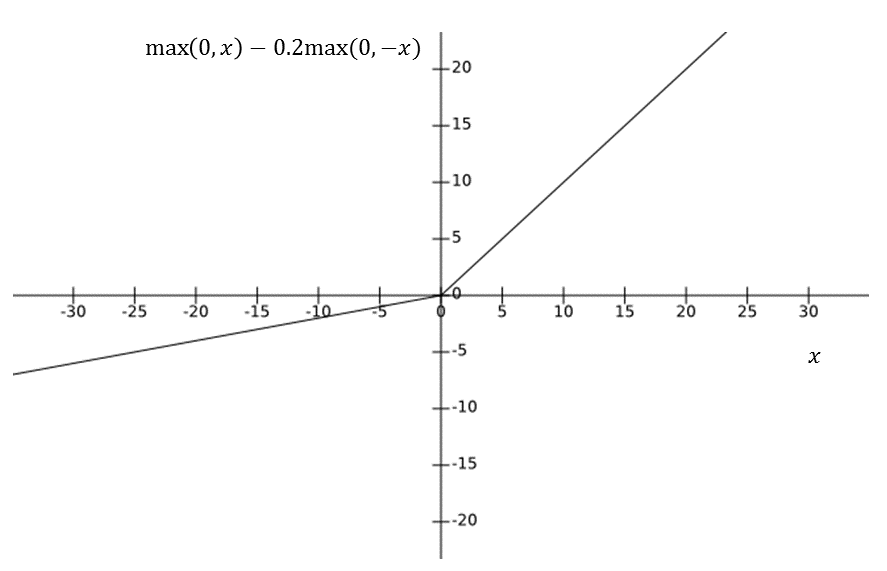
- ATmega16單片機(jī)項(xiàng)目驅(qū)動(dòng)教程
- 精選單片機(jī)設(shè)計(jì)與制作30例(第2版)
- 電腦軟硬件維修從入門到精通
- 嵌入式系統(tǒng)中的模擬電路設(shè)計(jì)
- CC2530單片機(jī)技術(shù)與應(yīng)用
- 筆記本電腦應(yīng)用技巧
- 單片機(jī)系統(tǒng)設(shè)計(jì)與開發(fā)教程
- 單片機(jī)開發(fā)與典型工程項(xiàng)目實(shí)例詳解
- 圖解計(jì)算機(jī)組裝與維護(hù)
- 電腦組裝與維護(hù)即時(shí)通
- 基于網(wǎng)絡(luò)化教學(xué)的項(xiàng)目化單片機(jī)應(yīng)用技術(shù)
- 微控制器的應(yīng)用
- 筆記本電腦維修技能實(shí)訓(xùn)
- 筆記本電腦的結(jié)構(gòu)、原理與維修
- 3D打印:Geomagic Design X5.1 逆向建模設(shè)計(jì)實(shí)用教程