- Apache Spark Quick Start Guide
- Shrey Mehrotra Akash Grade
- 446字
- 2021-07-02 13:39:56
Making the most of Hadoop and Spark
People generally get confused between Hadoop and Spark and how they are related. The intention of this section is to discuss the differences between Hadoop and Spark, and also how they can be used together.
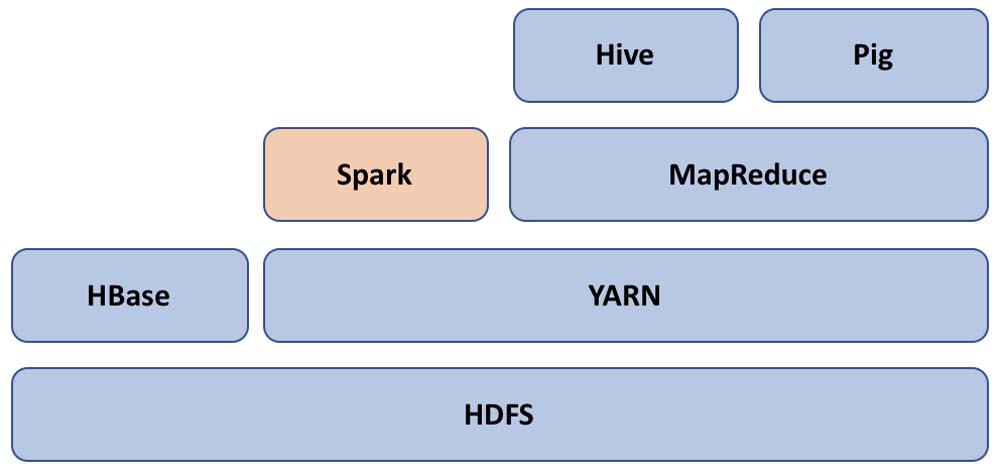
Hadoop is mainly a combination of the following components:
- Hive and Pig
- MapReduce
- YARN
- HDFS
HDFS is the storage layer where underlying data can be stored. HDFS provides features such as the replication of the data, fault tolerance, high availability, and more. Hadoop is schema-on-read; for instance, you don’t have to specify the schema while writing the data to Hadoop, rather, you can use different schemas while reading the data. HDFS also provides different types of files formats, such as TextInputFormat, SequenceFile, NLInputFormat, and more. If you want to know more about these file formats, I would recommend reading Hadoop: The Definitive Guide by Tom White.
Hadoop’s MapReduce is a programming model used to process the data available on HDFS. It consists of four main phases: Map, Sort, Shuffle, and Reduce. One of the main differences between Hadoop and Spark is that Hadoop’s MapReduce model is tightly coupled with the file formats of the data. On the other hand, Spark provides an abstraction to process the data using RDD. RDD is like a general-purpose container of distributed data. That’s why Spark can integrate with a variety of data stores.
Another main difference between Hadoop and Spark is that Spark makes good use of memory. It can cache data in memory to avoid disk I/O. On the other hand, Hadoop’s MapReduce jobs generally involve multiple disks I/O. Typically, a Hadoop job consists of multiple Map and Reduce jobs. This is known as MapReduce chaining. A MapReduce chain may look something like this: Map -> Reduce -> Map -> Map -> Reduce.
All of the reduce jobs write their output to HDFS for reliability; therefore, each map task next to it will have to read it from HDFS. This involves multiple disk I/O operations and makes overall processing slower. There have been several initiatives such as Tez within Hadoop to optimize MapReduce processing. As discussed earlier, Spark creates a DAG of operations and automatically optimizes the disk reads.
Apart from the previous differences, Spark complements Hadoop by providing another way of processing the data. As discussed earlier in this chapter, it integrates well with Hadoop components such as Hive, YARN, and HDFS. The following diagram shows a typical Spark and Hadoop ecosystem looks like. Spark makes use of YARN for scheduling and running its task throughout the cluster:
- 影視后期制作(Avid Media Composer 5.0)
- Mastering Salesforce CRM Administration
- Maya 2012從入門到精通
- Creo Parametric 1.0中文版從入門到精通
- 網絡安全管理實踐
- 青少年VEX IQ機器人實訓課程(初級)
- 貫通開源Web圖形與報表技術全集
- 筆記本電腦維修之電路分析基礎
- 與人共融機器人的關節力矩測量技術
- 企業級Web開發實戰
- 西門子S7-1200/1500 PLC從入門到精通
- Red Hat Enterprise Linux 5.0服務器構建與故障排除
- Mastering Android Game Development with Unity
- Hands-On Artificial Intelligence for Beginners
- 深度學習500問:AI工程師面試寶典