- Apache Spark Quick Start Guide
- Shrey Mehrotra Akash Grade
- 198字
- 2021-07-02 13:39:54
Spark architecture overview
Spark follows a master-slave architecture, as it allows it to scale on demand. Spark's architecture has two main components:
- Driver Program: A driver program is where a user writes Spark code using either Scala, Java, Python, or R APIs. It is responsible for launching various parallel operations of the cluster.
- Executor: Executor is the Java Virtual Machine (JVM) that runs on a worker node of the cluster. Executor provides hardware resources for running the tasks launched by the driver program.
As soon as a Spark job is submitted, the driver program launches various operation on each executor. Driver and executors together make an application.
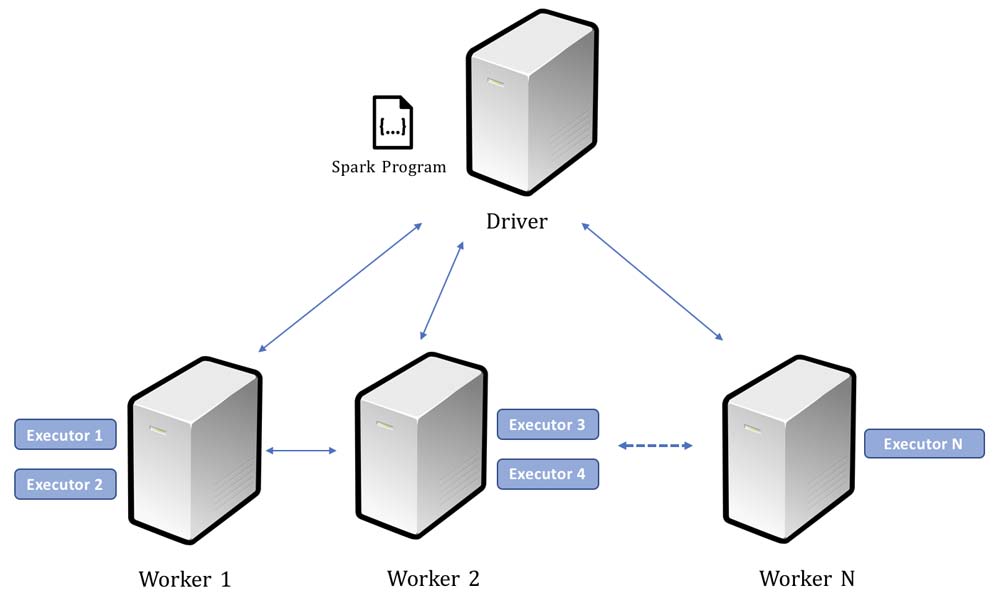
The following diagram demonstrates the relationships between Driver, Workers, and Executors. As the first step, a driver process parses the user code (Spark Program) and creates multiple executors on each worker node. The driver process not only forks the executors on work machines, but also sends tasks to these executors to run the entire application in parallel.
Once the computation is completed, the output is either sent to the driver program or saved on to the file system:
- Verilog HDL數字系統設計入門與應用實例
- Java開發技術全程指南
- 機器人智能運動規劃技術
- 數據挖掘實用案例分析
- JSF2和RichFaces4使用指南
- 完全掌握AutoCAD 2008中文版:綜合篇
- 工業控制系統測試與評價技術
- Grome Terrain Modeling with Ogre3D,UDK,and Unity3D
- Dreamweaver CS6精彩網頁制作與網站建設
- C++程序設計基礎(上)
- Moodle 2.0 Course Conversion(Second Edition)
- Mastering Android Game Development with Unity
- Mastering Microsoft Dynamics 365 Customer Engagement
- 嵌入式系統應用開發基礎
- 數字媒體交互設計原理與方法