- Hands-On Unsupervised Learning with Python
- Giuseppe Bonaccorso
- 315字
- 2021-07-02 12:32:06
Homogeneity score
The homogeneity score is complementary to the previous one and it's based on the assumption that a cluster must contain only samples having the same true label. It is defined as:
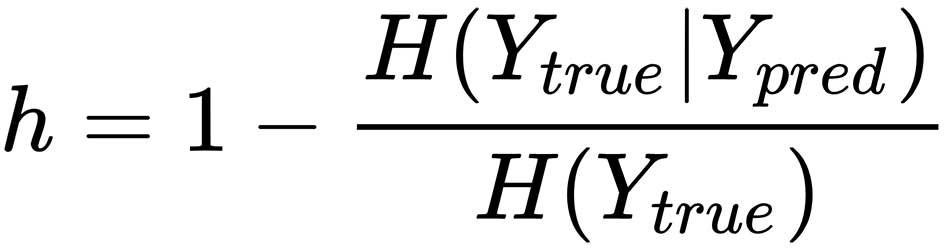
Analogously to the completeness score, when H(Ytrue|Ypred) → H(Ytrue), it means that the assignments have no impact on the conditional entropy, hence the uncertainty is not reduced after the clustering (for example, every cluster contains samples belonging to all classes) and h → 0. Conversely, when H(Ytrue|Ypred) → 0, h → 1, because knowledge of the predictions has reduced the uncertainty about the true assignments and the clusters contain almost exclusively samples with the same label. It's important to remember that this score alone is not enough, because it doesn't guarantee that a cluster contains all samples xi ∈ X with the same true label. That's why the homogeneity score is always evaluated together with the completeness score.
For the Breast Cancer Wisconsin dataset and K=2, we obtain the following:
from sklearn.metrics import homogeneity_score
print('Homogeneity: {}'.format(homogeneity_score(kmdff['diagnosis'], kmdff['prediction'])))
The corresponding output is as follows:
Homogeneity: 0.42229071246999117
This value (in particular, for K=2) confirms our initial analysis. At least one cluster (the one with the majority of benign samples) is not completely homogeneous, because it contains samples belonging to both classes. However, as the value is not very close to 0, we can be sure that the assignments are partially correct. Considering both values, h and c, we can deduct that K-means is not performing extremely well (probably because of non-convexity), but, at the same time, it's able to separate correctly all those samples whose nearest cluster distance is above a specific threshold. It goes without saying that, with knowledge of the ground truth, we cannot easily accept K-means and we should look for another algorithm that is able to yield both h and c → 1.
- 圖解西門子S7-200系列PLC入門
- 龍芯應用開發(fā)標準教程
- 極簡Spring Cloud實戰(zhàn)
- Camtasia Studio 8:Advanced Editing and Publishing Techniques
- Learning Stencyl 3.x Game Development Beginner's Guide
- The Deep Learning with Keras Workshop
- OUYA Game Development by Example
- Mastering Adobe Photoshop Elements
- R Deep Learning Essentials
- Spring Cloud微服務(wù)架構(gòu)實戰(zhàn)
- Rapid BeagleBoard Prototyping with MATLAB and Simulink
- RISC-V處理器與片上系統(tǒng)設(shè)計:基于FPGA與云平臺的實驗教程
- Istio服務(wù)網(wǎng)格技術(shù)解析與實踐
- “硬”核:硬件產(chǎn)品成功密碼
- Blender Game Engine:Beginner's Guide