- Mastering Docker Enterprise
- Mark Panthofer
- 571字
- 2021-07-02 12:30:08
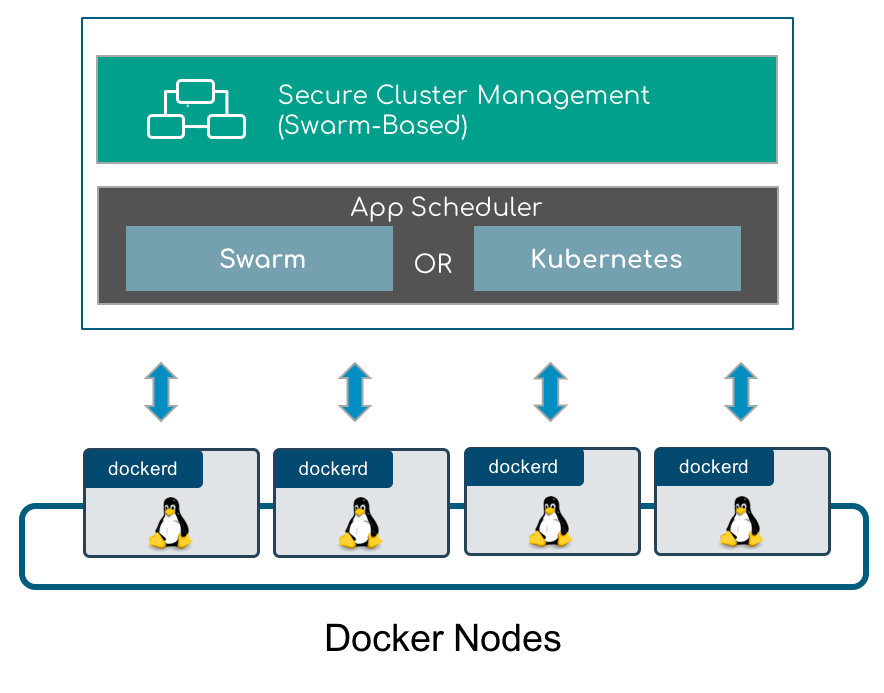
Simple view of the Docker Enterprise cluster architecture
Docker Enterprise provides a secure cluster management foundation that is backed by two orchestrators: Docker Swarm, built into Docker Engine-Community, and CNCF's Kubernetes, the leading born-in-the-cloud orchestration platform. When you install Docker Enterprise's Universal Control Plane (UCP), both orchestrators are installed and ready to go. This includes default overlay networking to allow container network communication between containers located on different nodes in the cluster and service discovery. Figure 5 illustrates your scheduler choice across a collection of cluster-managed worker nodes. Notice that Docker Enterprise relies on Swarm's secure cluster-based management as a foundation for both orchestrators. Figure 6 shows a simple Docker Swarm TLS encrypted cluster:
Peeling the onion one layer deeper reveals how a HA cluster includes multiple manager nodes in addition to the worker nodes, and how all intra-node communications are TLS encrypted. When a Swarm cluster is created, the first manager establishes a Certificate Authority (CA) and uses the CA's certificate authority to sign and secure the certificates exchanged when adding nodes to the cluster, using a secure join token. Additionally, the managers rotate the certificates at a configurable interval in case one of the certificates should be compromised over time:

Often, in the early stages of Docker adoption and usually prior to Docker Enterprise adoption, it is common to have a simple Docker Swarm cluster with a single manager node and a few worker nodes. However, as enterprises migrate to Docker Enterprise, availability, security, and scale become the focus. The reference architecture shown in Figure 7 reflects a highly available Docker Enterprise cluster with three UCP managers, three DTR replicas, three worker nodes, and three load balancers spread across three availability zones. Please note, you could add a hundred or more additional workers without adding any more manager or DTR nodes:

Docker Enterprise UCP is installed on top of Docker Swarm managers. In this configuration, if a manager node is lost, the cluster keeps running. The same is true for the DTR. In fact, slicing UCP and DTR across availability zones allows the cluster to stay running even if one of the availability zones fails. It is important to note that, while the cluster, and more importantly the applications in the cluster, keep running, the cluster may report an unhealthy state. This means operators need to restore any unhealthy managers or DTR replicas as soon as possible to restore a quorum to the cluster ASAP and ensure that the cluster remains available.
Please note all of the primary interfaces to the cluster (UCP—admin interface, DTR—image management interface and application access) are all frontended with a load balancer. UCP and DTR both have health check endpoints for the load balancers to verify service availability. The application load balancers are usually a little different in that each application needs to implement its own health checks. Also, the application load balancing configuration is likely broken into two parts. The first part is a classic load balancer responding to the application DNS target (often something like *.app.mydomain.com) and it forwards traffic to instances of reverse proxy servers running in the cluster. There will be a more detailed discussion on layer-7 routing later in the book.
- 高性能混合信號ARM:ADuC7xxx原理與應用開發
- 程序設計缺陷分析與實踐
- 極簡AI入門:一本書讀懂人工智能思維與應用
- Dreamweaver CS3網頁設計與網站建設詳解
- Windows XP中文版應用基礎
- VMware Performance and Capacity Management(Second Edition)
- 工業機器人入門實用教程(KUKA機器人)
- 計算機網絡原理與技術
- Dreamweaver CS6精彩網頁制作與網站建設
- 工業機器人集成應用
- Cortex-M3嵌入式處理器原理與應用
- RealFlow流體制作經典實例解析
- Linux常用命令簡明手冊
- Getting Started with Tableau 2018.x
- 網管員世界2009超值精華本