- Hands-On Big Data Analytics with PySpark
- Rudy Lai Bart?omiej Potaczek
- 332字
- 2021-06-24 15:52:32
Setting up Spark on Windows and PySpark
Complete the following steps to install PySpark on a Windows machine:
- Download Gnu on Windows (GOW) from https://github.com/bmatzelle/gow/releases/download/v0.8.0/Gow-0.8.0.exe.
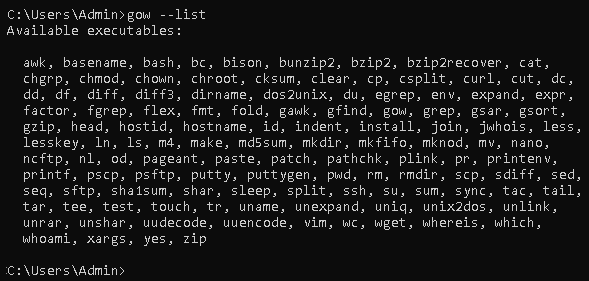
- GOW allows the use of Linux commands on Windows. We can use the following command to see the basic Linux commands allowed by installing GOW:
gow --list
This gives the following output:
- Download and install Anaconda. If you need help, you can go through the following tutorial: https://medium.com/@GalarnykMichael/install-python-on-windows-anaconda-c63c7c3d1444.
- Close the previous command line and open a new command line.
- Go to the Apache Spark website (https://spark.apache.org/).
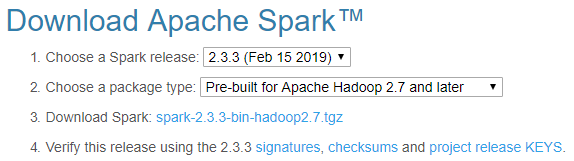
- To download Spark, choose the following from the drop-down menu:
- A recent Spark release
- A proper package type
The following screenshot shows the download page of Apache Spark:
- Then, download Spark. Once it is downloaded, move the file to the folder where you want to unzip it.
- You can either unzip it manually or use the following commands:
gzip -d spark-2.1.0-bin-hadoop2.7.tgz
tar xvf spark-2.1.0-bin-hadoop2.7.tar
- Now, download winutils.exe into your spark-2.1.0-bin-hadoop2.7\bin folder using the following command:
curl -k -L -o winutils.exe https://github.com/steveloughran/winutils/blob/master/hadoop-2.6.0/bin/winutils.exe?raw=true
- Make sure you have Java installed on your machine. You can use the following command to see the Java version:
java --version
This gives the following output:

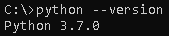
- Check for the Python version by using the following command:
python --version
This gives the following output:
- Let's edit our environmental variables so that we can open Spark in any directory, as follows:
setx SPARK_HOME C:\opt\spark\spark-2.1.0-bin-hadoop2.7
setx HADOOP_HOME C:\opt\spark\spark-2.1.0-bin-hadoop2.7
setx PYSPARK_DRIVER_PYTHON ipython
setx PYSPARK_DRIVER_PYTHON_OPTS notebook
Add C:\opt\spark\spark-2.1.0-bin-hadoop2.7\bin to your path.
- Close the Terminal, open a new one, and type the following command:
--master local[2]
The PYSPARK_DRIVER_PYTHON and the PYSPARK_DRIVER_PYTHON_OPTS parameters are used to launch the PySpark shell in Jupyter Notebook. The --master parameter is used for setting the master node address.
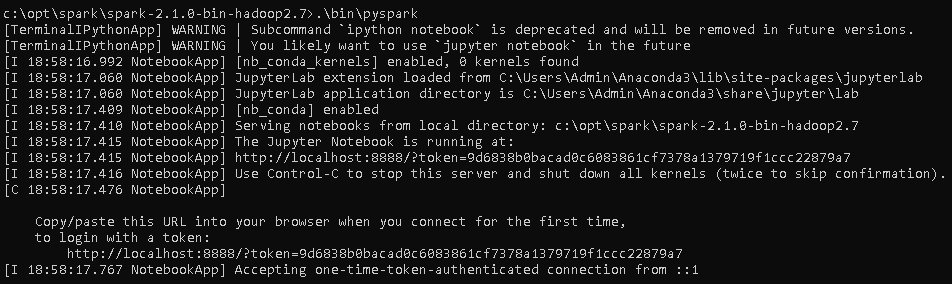
- The next thing to do is to run the PySpark command in the bin folder:
.\bin\pyspark
This gives the following output:
推薦閱讀
- PyTorch深度學習實戰(zhàn):從新手小白到數據科學家
- 數據產品經理高效學習手冊:產品設計、技術常識與機器學習
- Python金融大數據分析(第2版)
- Voice Application Development for Android
- Live Longer with AI
- Lean Mobile App Development
- 大話Oracle Grid:云時代的RAC
- 數據庫原理與應用(Oracle版)
- Starling Game Development Essentials
- ZeroMQ
- 云原生數據中臺:架構、方法論與實踐
- Power BI智能數據分析與可視化從入門到精通
- Python數據分析從小白到專家
- 智慧城市中的大數據分析技術
- 數字化轉型實踐:構建云原生大數據平臺