- Geospatial Data Science Quick Start Guide
- Abdishakur Hassan Jayakrishnan Vijayaraghavan
- 333字
- 2021-06-24 13:48:19
Exploratory data analysis
For this chapter, we will be using curated data from the New York taxi trip dataset provided by the city of New York. The original source for this data can be found here: https://data.cityofnewyork.us/api/odata/v4/hvrh-b6nb.
For starters, let's have a peek at the data at hand using pandas. The curated data (NYC_sample.csv) that we will be using here can be found at the following download link: https://drive.google.com/file/d/1OkkYZJEcsdCkU0V42eP6pj6YaK2WCGCE/view.
df = pd.read_csv("NYC_sample.csv")
df.head().T
The curated New York taxi trip data that we are using has around 1.14 million records and has columns related to taxi fare, as well as trip duration, as you can see from the following screenshot:
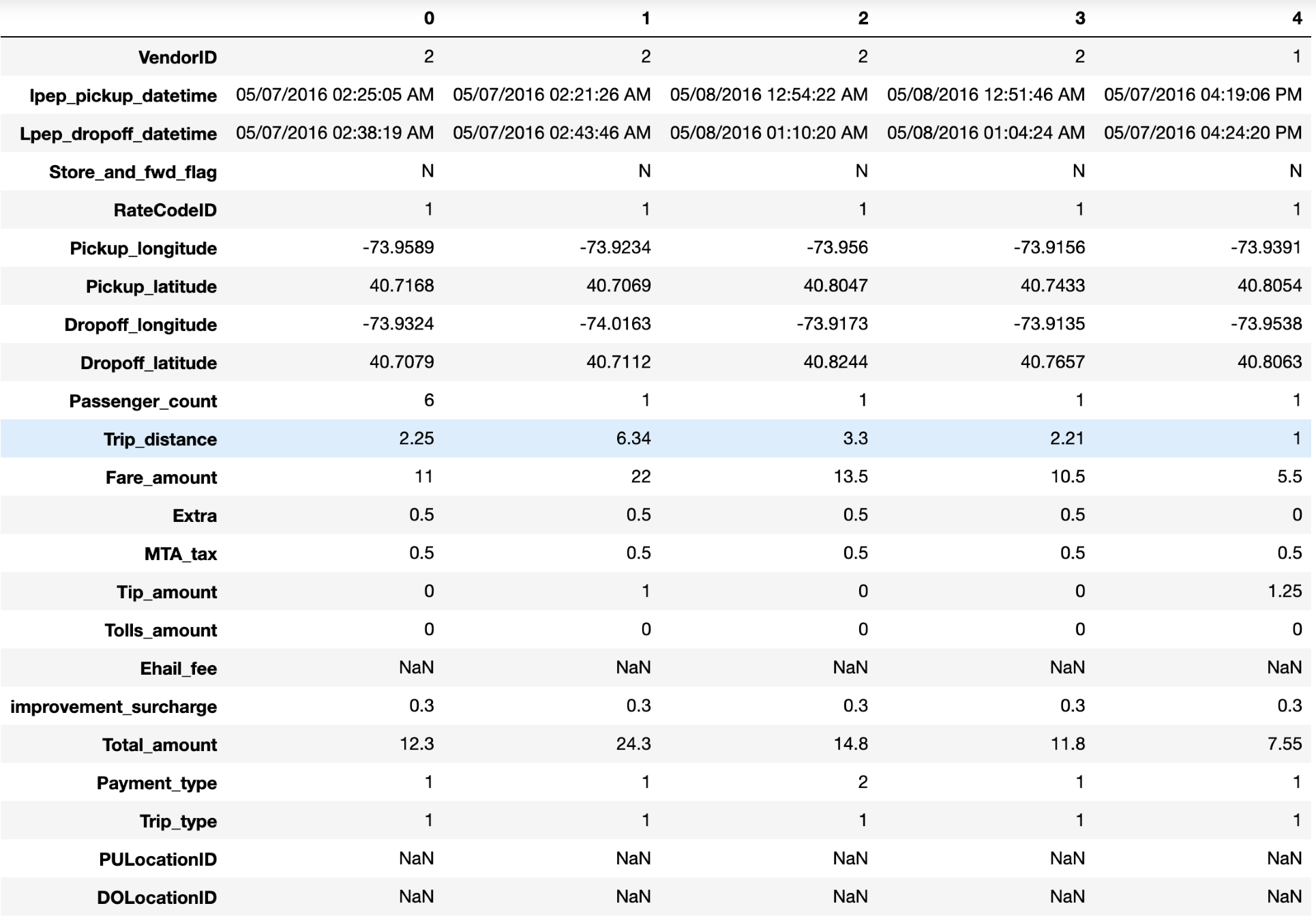
The data dictionary for this data that can be found at https://data.cityofnewyork.us/api/views/hvrh-b6nb/files/65544d38-ab44-4187-a789-5701b114a754?download=true&filename=data_dictionary_trip_records_green.pdf. The data download page provides us with useful information about the data.
We can make the following inferences and assumptions about processing the data:
- Some columns have missing values (NaN included) that need to be handled.
- The value that we are trying to predict for each trip is the trip duration. This needs to be derived from the pickup and dropoff times for the training and validation data.
- Once the trip duration has been derived, we need to get rid of the dropoff time information since our objective is to compute the dropoff time when given other information, such as pickup location and time and dropoff location.
- We intend to primarily use the pickup and dropoff locations to predict time. Hence, in the training phase, we should be dropping records that don't have pickup and dropoff location information.
- We'd like to exclude columns related to trip cost because it doesn't contribute to the model.
We can do the following to tackle the problems we identified by taking a cursory glance at the data:
- Handle missing values
- Handle time values
- Handle unrelated data