- PyTorch 1.x Reinforcement Learning Cookbook
- Yuxi (Hayden) Liu
- 243字
- 2021-06-24 12:34:46
Performing policy evaluation
We have just developed an MDP and computed the value function of the optimal policy using matrix inversion. We also mentioned the limitation of inverting an m * m matrix with a large m value (let's say 1,000, 10,000, or 100,000). In this recipe, we will talk about a simpler approach called policy evaluation.
Policy evaluation is an iterative algorithm. It starts with arbitrary policy values and then iteratively updates the values based on the Bellman expectation equation until they converge. In each iteration, the value of a policy, π, for a state, s, is updated as follows:
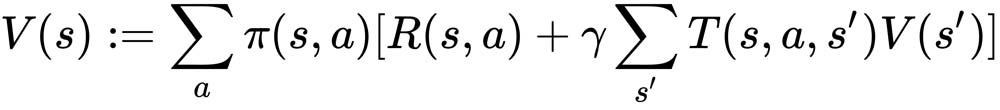
Here, π(s, a) denotes the probability of taking action a in state s under policy π. T(s, a, s') is the transition probability from state s to state s' by taking action a, and R(s, a) is the reward received in state s by taking action a.
There are two ways to terminate an iterative updating process. One is by setting a fixed number of iterations, such as 1,000 and 10,000, which might be difficult to control sometimes. Another one involves specifying a threshold (usually 0.0001, 0.00001, or something similar) and terminating the process only if the values of all states change to an extent that is lower than the threshold specified.
In the next section, we will perform policy evaluation on the study-sleep-game process under the optimal policy and a random policy.
- Introduction to DevOps with Kubernetes
- 工業機器人產品應用實戰
- TestStand工業自動化測試管理(典藏版)
- 計算機控制技術
- Visual C# 2008開發技術詳解
- 21天學通Visual Basic
- ESP8266 Home Automation Projects
- 人工智能實踐錄
- 大數據時代
- 運動控制系統應用與實踐
- Grome Terrain Modeling with Ogre3D,UDK,and Unity3D
- Mastering Text Mining with R
- Getting Started with Tableau 2018.x
- 網絡信息安全項目教程
- 開放自動化系統應用與實戰:基于標準建模語言IEC 61499