- 人工智能:語音識別理解與實踐
- 俞棟等
- 1342字
- 2021-01-05 18:14:46
1.2 語音識別系統的基本結構
圖1-2中展示的是語音識別系統的基本結構,語音識別系統主要由4部分組成:信號處理和特征提取、聲學模型(AM)、語言模型(LM)和解碼搜索。
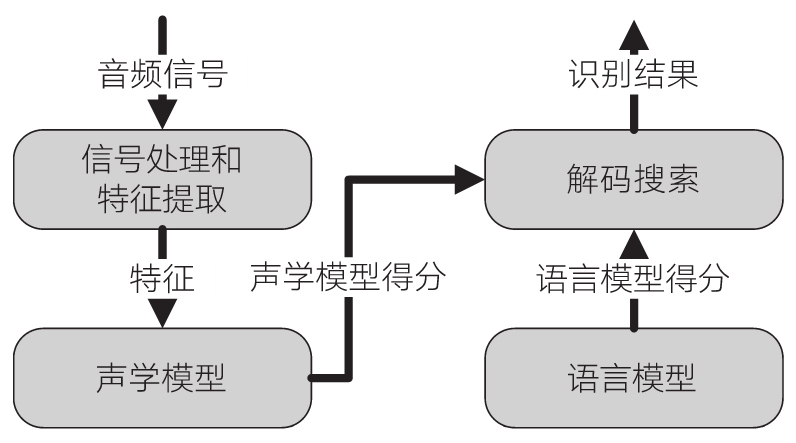
圖1-2 語音識別系統的基本架構
信號處理和特征提取部分以音頻信號為輸入,通過消除噪聲和信道失真對語音進行增強,將信號從時域轉化到頻域,并為后面的聲學模型提取合適的有代表性的特征向量。聲學模型將聲學和發音學(Phonetics)的知識進行整合,以特征提取部分生成的特征為輸入,并為可變長特征序列生成聲學模型分數。語言模型估計通過訓練語料(通常是文本形式)學習詞之間的相互關系,來估計假設詞序列的可能性,又叫語言模型分數。如果了解領域或任務相關的先驗知識,則語言模型分數通常可以估計得更準確。解碼搜索對給定的特征向量序列和若干假設詞序列計算聲學模型分數和語言模型分數,將總體輸出分數最高的詞序列作為識別結果。本書將集中討論語音識別中的聲學模型技術,并在第13章中對深度學習語言模型進行介紹。
關于聲學模型,有兩個主要問題,分別是特征向量序列的可變長和音頻信號的豐富變化性。可變長特征向量序列的問題在學術上通常由動態時間規整(Dynamic Time Warping,DTW)方法和將在第3章描述的隱馬爾可夫模型(HMM)[7]方法來解決。音頻信號的豐富變化性(variable)是由說話人的各種復雜的特性(如性別、健康狀況或緊張程度)交織引起的,或是由說話風格與速度、環境噪聲、周圍人聲(Side Talk)、信道扭曲(Channel Distortion)(如麥克風間的差異)、方言差異、非母語口音(Non-native Accent)引起的。一個成功的語音識別系統必須能夠應付所有這類聲音的變化因素。
像我們在1.1節中討論的那樣,從特定領域任務向真實應用轉變時,會遇到一些困難。如圖1-3所示,一個時下實際的語音識別系統需要處理大詞匯量(數百萬)、自由式對話、帶噪聲的遠場自發語音和多語言混合的問題。
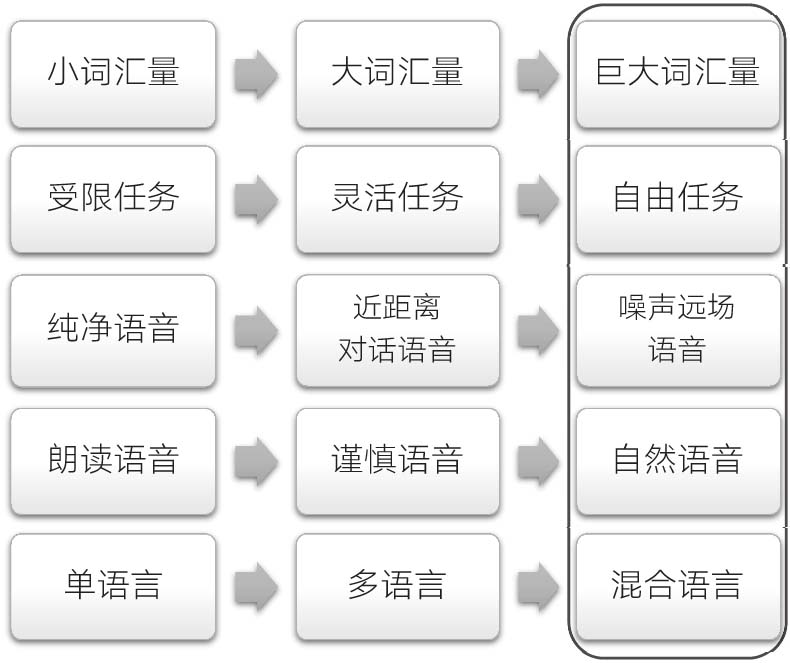
圖1-3 從特定領域向真實應用的轉變
在過去,最流行的語音識別系統通常使用梅爾倒譜系數(MelFrequency Cepstral Coefficient,MFCC)[8]或者相對頻譜變換-感知線性預測(Perceptual Linear Prediction,PLP)[9]作為特征向量,使用混合高斯模型-隱馬爾可夫模型(Gaussian mixture model-HMM,GMM-HMM)作為聲學模型。20世紀90年代,最大似然準則(Maximum Likelihood,ML)被用來訓練這些GMM-HMM聲學模型。到了21世紀,序列鑒別性訓練算法(Sequence Discriminative Training Algorithm)如最小分類錯誤(Minimum Classification Error,MCE)[10]和最小音素錯誤(Minimum Phone Error,MPE)[11]等準則被提了出來,并進一步提高了語音識別的準確率。
近些年,分層鑒別性模型(Discriminative Hierarchical Model)如深層神經網絡(Deep Neural Network,DNN)[12]依靠不斷增長的計算力、大規模數據集的出現和人們對模型本身更好的理解,變得可行起來,它們顯著地減小了錯誤率。舉例來說,上下文相關的深層神經網絡-隱馬爾可夫模型(Context-Dependent DNN-HMM,CD-DNN-HMM)與傳統的使用序列鑒別準則(Sequence Discriminative Criteria)[13]訓練的GMM-HMM系統相比,在Switchboard對話任務上錯誤率降低了三分之一。
在本書中,我們將介紹這些分層鑒別性模型的最新研究進展,包括深層神經網絡、卷積神經網絡(Convolutional Neural Network,CNN)和循環神經網絡(Recurrent Neural Network,RNN)。同時,對于深度學習在先進的語音識別技術框架下的應用,如自適應、鑒別性訓練等,以及復雜場景下的語音識別技術,如多語種、環境噪聲、遠場識別等,也會給予詳細介紹。我們將討論這些模型的理論基礎和使系統能夠正常工作的實踐技巧。由于我們對自己所做的工作比較熟悉,本書主要著眼于我們自己的工作,當然,在需要的時候也會涉及其他研究者的相關研究。