- Elastic Stack應用寶典
- 田雪松編著
- 3311字
- 2020-07-22 17:21:24
2.3 字段數據類型
通過映射類型的properties字段,可以定義映射類型包含的字段及其數據類型。例如在示例2-7中,age字段的數據類型為keyword,而address字段的數據類型則為text。Elasticsearch支持的數據類型包括字符串、數值、日期、布爾、二進制、范圍等核心數據類型,還支持數組、對象等衍生類型,也支持嵌套、關聯、地理信息等特殊類型。由于衍生類型和特殊類型基本都是從核心類型派生而來,所以下面先介紹一下核心數據類型。對于特殊數據類型,將在本書第8章結合具體應用介紹。
2.3.1 核心類型
核心數據類型是字段數據類型的基礎,它們涵蓋了大多數文檔字段的應用場景。核心類型可以分為字符串、數值、日期、布爾等幾種大的類型,每種大的類型下可能會包含一些更具體的數據類型。
1.字符串類型
字符串類型包括text和keyword兩種類型,兩者的區別在于text類型在存儲前會做詞項分析,而keyword類型則不會。所以text類型的字段可以通過analyzer參數設置該字段的分析器,而keyword類型字段則沒有這個參數。由于詞項分析,text類型字段在編入索引后可通過詞項做檢索,但不能通過字段整體值做檢索;而keyword類型字段則剛好相反,只能通過字段整體值來做檢索而不能用詞項做檢索。所以text類型的字段一般用于存儲全文數據,比如日志信息、文章正文、郵件內容等;而keyword類型則用于存儲結構化的文本數據,如郵編、地址、電話等。
由于text類型存儲的是全文本數據,所以它編入索引的信息包括文檔ID、詞頻、詞序等信息,而keyword類型則只編入文檔ID。當然,這可以通過index_option參數修改。在存儲方面,keyword類型默認就支持通過文檔值機制保存字段原始值,可通過doc_values參數關閉這個機制。text類型則不支持文檔值機制,所以text類型不能參與文檔排序、過濾、聚集等操作,除非打開它的fielddata機制。
2.數值類型
數值類型對應一個具體的數字值,例如1024、3.14等。Elasticsearch支持包括整型、浮點類型在內的8種數值類型,它們的主要區別體現的數值精確度上,具體見表2-4。
表2-4 數值類型

(續)
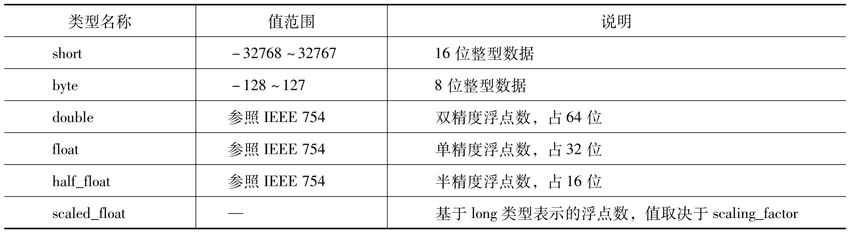
在這些類型中比較特殊的一類是scaled_float,它雖然是浮點數據類型,但在存儲上卻是使用long類型來表示。其基本思想是通過一個換算系數將浮點數放大為整型再保存,例如設置3.14的換算系數為100,則換算結果為3.14×100=314,最終保存的值就是314。由于使用整型保存浮點數不僅不會損失精度還能提升運算效率,所以非常適合小數位數固定的數值,比如貨幣金額通常就只有兩個小數位。設置scaled_float的換算系數時可使用scaling_factor,例如

示例2-8 scaling_factor
對于整型數據來說,應該在滿足需求的前提下選擇盡可能小的數據類型,這對于提升索引和搜索性能都有幫助。如果不清楚最終數值的范圍,可以不顯式設置它們的類型而由Elasticsearch自主判斷,以防止實際數值范圍溢出。
3.日期類型
Elasticsearch有兩種日期類型,分別是date和date_nanos。由于JSON并沒有日期類型,所以這兩種類型在文檔中表現出來的仍然是帶有日期格式的字符串。但在Elasticsearch內部存儲它們時,會將它們轉換為該日期與計算機紀元(1970年1月1日0點)的時間差值。其中,date類型會按毫秒計算差值,而date_nanos則會按納秒計算差值。由于Elasticsearch在實現上使用long類型保存這個差值,這使得date_nanos類型能夠保存的時間最多只能到2262年。所以在使用date_nanos類型時,要注意時間范圍是否超標。
不管是哪一種日期類型,它們都必須滿足一定的格式要求。如果沒有指定格式默認會使用ISO 8601定義的標準時間格式,類似于“yyyy-MM-ddTHH:mm:ss”的形式。當然,這種格式有比較嚴格的定義,可以在相關文檔中找到它們的規范。除此之外,默認格式也支持使用毫秒數直接表示日期。通過format參數還可以自定義日期格式,支持使用類似“yyyy-MM-ddTHH:mm:ss”的JODA格式來描述。相信有一定Java開發經驗的讀者應該不難理解,這里不再贅述。除此之外,Elasticsearch還內置了一組常用日期格式,可直接使用這些日期格式的名稱來定義日期。這些日期格式非常多,詳細請參考:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html。
4.布爾類型
布爾類型的類型關鍵字是boolean,它只有兩個值,即true和false。但也接收以字符串描述的true和false,即使用 "true" 和 "false" 也是合法的。
5.字節類型
字節類型接收以Base64編碼后表示的二進制字節流,所以盡管它的類型是字節類型,但在文檔中它表現出來的仍然是字符串。字節類型的字段在默認情況下不會被存儲,也不會被檢索到。
6.范圍類型
范圍類型要求字段的值描述的是一個數值、日期或IP地址的范圍,添加文檔時可以使用gte、gt、lt、lte分別表示大于等于、大于、小于、小于等于。數值范圍類型包括integer_range、float_range、long_range、double_range,日期范圍類型和IP范圍類型分別為date_range和ip_range。例如在示例2-9中先定義了age_range字段的類型為integer_range,然后又添加了一個age_range范圍為[7, 23)的文檔。所以在檢索age_range為10時就會返回添加的新文檔。


示例2-9 范圍類型
在使用date_range和ip_range時需要注意它們的格式,對于日期可以使用format定義日期格式,而IP地址除了可以使用上述方式表示以外,還可以使用CIDR表示法描述一個網段。
2.3.2 衍生類型
衍生類型從核心類型衍生而來,包括數組和對象兩種。嚴格來說,它們并不是獨立的數據類型,因為它們并不像核心數據類型那樣有專門的類型名稱,而是通過特定的JSON格式確認它們的類型。
1.數組
如果要定義一個字段為數組類型,不需要使用類似array這樣的名稱聲明它的類型,而是通過在添加文檔時使用“[]”來確認該字段為數組。Elasticsearch也沒有定義array這種數據類型,數組是在核心數據類型基礎上的一種擴展。只要字段聲明為某種核心數據類型,那么它就可以接收以“[]”表示的數組。惟一的限制就是數組中的元素必須是同一種類型,或者它們至少可以轉換為同一種類型。如果在索引定義中聲明了屬性的數據類型,則數組元素的類型必須要與這種類型一致,或者可以轉換為這種類型。例如:

示例2-10 數組類型
在示例2-10中,["12","2"]雖然為字符串的數組,但由于它們可以轉換為整型,所以可以賦值給整型字段。
2.對象
與數組類似,Elasticsearch中也沒有定義object這種數據類型,它是在添加文檔時使用“{}”的格式來確認字段類型為對象。例如:


示例2-11 對象類型
在示例2-11中,address就是一個對象,包含了country和city兩個字段。與數組類型不同的是,對象類型在定義索引的映射關系時可以聲明。具體方式是使用嵌套的properties屬性,例如在示例2-11中的colleges索引可以這樣定義:

示例2-12 聲明對象類型
2.3.3 多數據類型
有些文檔字段可能經常會以不同的方式檢索,如果文檔字段只以一種方式編入索引,檢索性能就會受到影響。比如文章的標題,在多數情況下可能是通過文章標題中的詞項做檢索,但在標題比較短并且知道整個標題內容時也是有可能使用整個標題做檢索的。如果將標題字段的類型設置為text,那么標題在編入索引時就會被提取詞項而不能使用整個標題做檢索,而如果設置為keyword則不能使用詞項做檢索。事實上更為重要的是text類型并不支持文檔值機制,所以通過text類型做排序或聚集就必須開啟fielddata機制,而這種機制對于內存的消耗又非常大。
所以針對字符串類型text和keyword,Elasticsearch專門提供了一個用于配置字段多數據類型的參數fields,它能讓一個字段同時具備兩種數據類型的特征。示例2-13就是將articles索引的title字段設置為兩種數據類型:

示例2-13 多數據類型
在示例2-13中,title字段的類型被設置為text,同時通過fields參數又為該字段添加了兩個子字段。其中一個子字段名稱為raw,它的類型被設置為keyword類型;另一個子字段名稱為length,它的類型則為token_count。使用fields設置的子字段,在添加文檔時不需要單獨設置值,它們與title共享相同的字段值,只是會以不同方式處理字段值。同樣,在檢索時,它們也不會單獨顯示在結果中。所以它們一般只是在檢索中以查詢條件的形式出現,以減少檢索時的性能開銷。例如對于title.raw來說,title字段在編入索引時會將字段值做分析并提取詞項,而title.raw則按keyword類型將整個值編入索引。所以如果需要根據詞項做檢索時應使用title字段,而如果需要使用整個值做檢索或是在排序和聚集時則可以使用title.raw字段。在默認情況下,如果沒有明確定義字符串類型時,添加到索引中的字符串都會以示例2-13的形式設置為多類型。
再來看另外一個字段title.length,它被設置為一種新的數據類型token_count。這種數據類型保存的值為整型,但實際接收的內容卻是title字段的字符串。它會將字符串做分析并提取詞項,然后將詞項的數量保存下來,所以token_count類型字段必須要通過analyzer參數設置提取詞項使用的分析器。由于title.length字段也是通過fields參數添加進來的,所以它在檢索結果中也不會出現。需要注意的是,即使token_count類型不是通過fields參數添加進來的字段,它在檢索結果的_source字段中仍然是原始的字符串,因為_source字段保存的是源文檔而不是字段實際編入索引的值。如果一定要查看token_count類型字段保存的實際值,可以使用第4章第4.4.3節介紹的docvalue_fields查詢方式。
- Java Web開發學習手冊
- Java程序設計(慕課版)
- 神經網絡編程實戰:Java語言實現(原書第2版)
- Eclipse Plug-in Development:Beginner's Guide(Second Edition)
- Redis Essentials
- GeoServer Beginner's Guide(Second Edition)
- Learning OpenStack Networking(Neutron)
- Mastering JavaScript High Performance
- Mastering JavaScript Design Patterns(Second Edition)
- 51單片機C語言開發教程
- Mobile Device Exploitation Cookbook
- 細說Python編程:從入門到科學計算
- SQL Server 2008 R2數據庫技術及應用(第3版)
- 石墨烯改性塑料
- Software-Defined Networking with OpenFlow(Second Edition)