- Excel革命!超級數據透視表Power Pivot與數據分析表達式DAX快速入門
- 林書明
- 11457字
- 2020-07-28 11:17:49
2.4 Power Pivot與DAX函數
在數據透視表值區域中的每個單元格中的內容都是其對應的數據透視表篩選環境(行標題、列標題、篩選字段、切片器、日程表等)到數據源中篩選后匯總得到的結果。
在很多場景中,我們需要修改數據透視表篩選環境,從而滿足更加復雜的數據分析需求。這時就需要各種用途的DAX函數上場了。
很多DAX函數與Excel工作表函數大不相同。在一般情況下,Excel工作表函數的計算結果是一個數值;很多DAX函數的計算結果不是一個簡單的數值,可能是一個表,也可能是改變Power Pivot數據模型的一些篩選設置。
2.4.1 篩選限制移除函數——ALL()函數
在數據分析實戰中,經常需要計算各種占比,如在數據透視表值區域中計算每個圖書子類銷售冊數占圖書大類銷售冊數的百分比,此時就要用到篩選限制移除函數——ALL()函數了。
ALL()函數的功能:在數據透視表篩選環境中移除指定字段或整個表上的篩選限制。
ALL()函數的參數可以是一個表(此時只能有一個參數),也可以是一個表中的一列或幾列。當ALL()函數的參數是一個表中的一列或幾列時,要求所有列必須來自同一個表。
ALL()函數一般會與其他DAX函數一起使用,如與CALCULATE()函數一起使用,用于修改這些函數所處的數據透視表篩選環境。
需要注意的是,當ALL()函數的參數是特定表上的指定列時,它能夠移除該表指定列上的篩選限制,并且這種篩選移除效果會影響整個表,就像我們在Excel工作表中移除位于某列上的篩選限制一樣。
1.ALL()函數的參數是表中的一列
ALL()函數通常用于計算子類與其所屬大類的比值。針對本書中的案例,我們有如下數據分析需求:計算每個圖書子類的銷售總冊數與其所屬圖書大類的銷售總冊數的比值。
首先,在Power Pivot數據模型管理界面中的“T3銷售”表下方的DAX表達式編輯區中的單元格中添加如下DAX表達式:

上述操作如下圖所示。
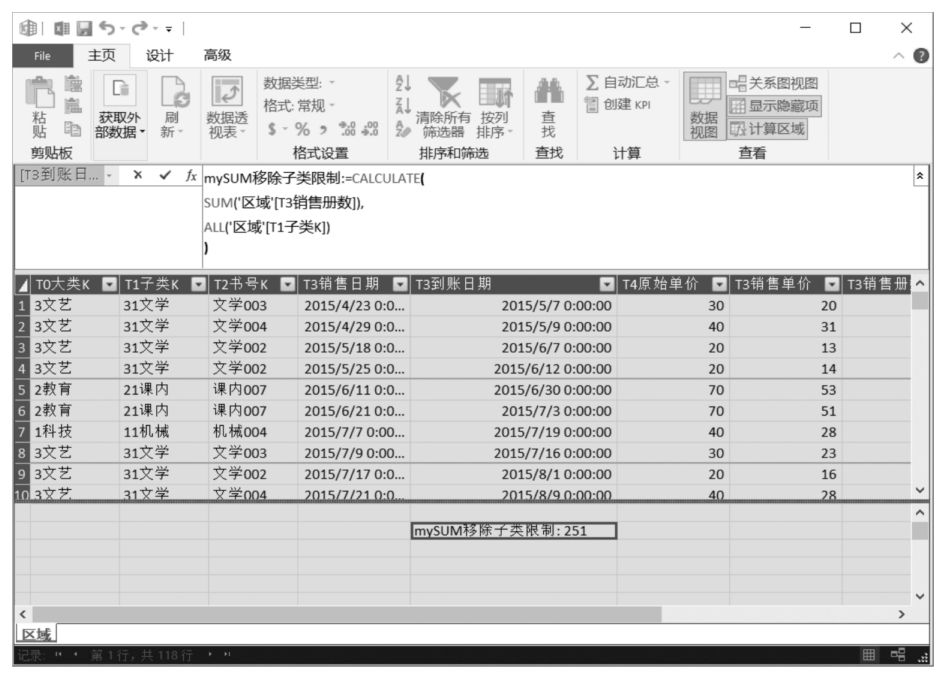
上述DAX表達式與我們之前所見的DAX表達式的區別是CALCULATE()函數中增加了第二個參數(ALL('區域'[T1子類K])),該參數是一個嵌入CALCULATE()函數內部的DAX表達式,類似于Excel工作表函數中的函數嵌套。
這里,作為CALCULATE()函數的第二個參數(篩選器參數),ALL('區域'[T1子類K])的功能是在CALCULATE()函數所處的數據透視表篩選環境中移除篩選條件[T1子類K],換句話說就是從數據透視表值區域對應的所有數據透視表篩選環境中移除“T1子類K”字段的特定篩選限制,即對數據透視表篩選環境做減法,放松了篩選限制。
將DAX表達式“mySUM移除子類限制”拖曳至數據透視表值區域中,計算結果如下圖所示。
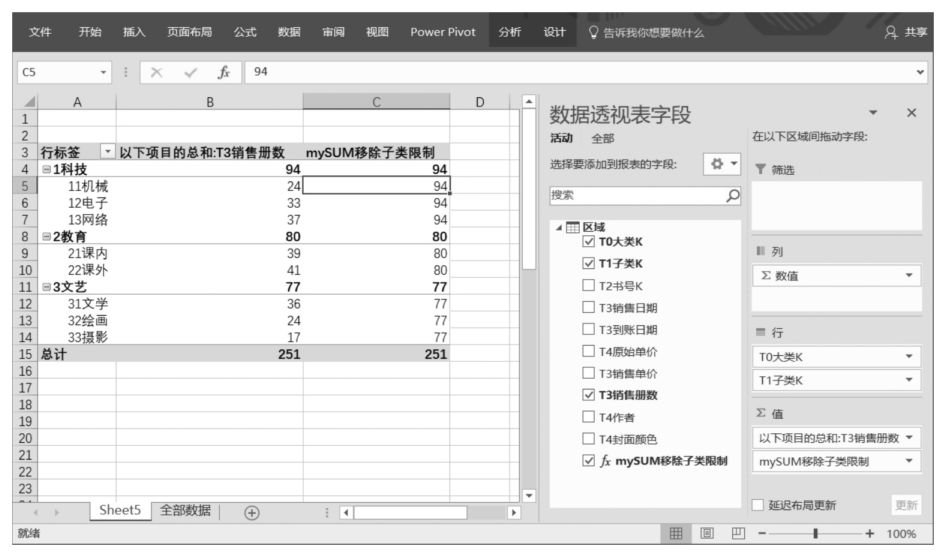
觀察上圖可知,雖然“T1子類K”字段仍然位于數據透視表的行標題中,但它對數據透視表值區域中的DAX表達式“mySUM移除子類限制”的篩選限制消失了,而數據透視表最左側的行標題“T0大類K”對該DAX表達式的篩選限制依然存在,這是因為ALL()函數移除的只是“T1子類K”字段對該DAX表達式的篩選限制,并沒有移除“T0大類K”字段對該DAX表達式的篩選限制。
觀察數據透視表值區域中的C5單元格,該單元格中的內容對應的數據透視表篩選環境為“1科技”圖書大類、“11機械”圖書子類。在沒有移除任何數據透視表篩選環境限制時,“1科技”圖書大類下的“11機械”圖書子類的銷售總冊數為24 (B5單元格對應的數值);在用ALL()函數在DAX表達式“mySUM移除子類限制”中移除了“T1子類K”字段的篩選限制后,這個數值反映的是它的上一級(“1科技”圖書大類)的銷售總冊數為94。
在掌握了ALL()函數的基本功能后,就可以利用DAX函數計算每個圖書子類的銷售總冊數與其所屬圖書大類的銷售總冊數的比值了。
由于我們已經設計好了移除圖書子類限制的DAX表達式,因此以這個DAX表達式為分母,以沒有移除數據透視表篩選環境中任何篩選限制的圖書銷售總冊數的DAX表達式為分子,即可得到每個圖書子類銷售總冊數與其所屬圖書大類的銷售總冊數的比值。
沒有移除數據透視表篩選環境中任何篩選限制的圖書銷售總冊數的DAX表達式如下:

計算圖書子類的銷售總冊數與其所屬圖書大類的銷售總冊數的比值的DAX表達式如下:

這三個DAX表達式在Power Pivot數據模型管理界面中的呈現形式如下圖所示。
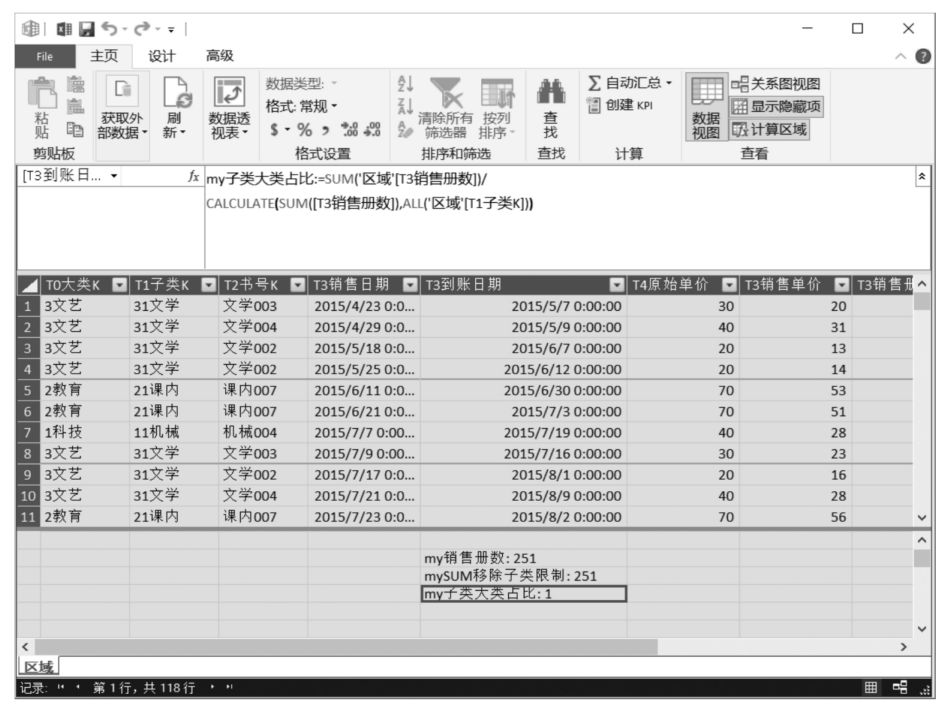
在Power Pivot數據模型管理界面,單擊“數據透視表”按鈕,在彈出的下拉列表中選擇“數據透視表”命令,切換到Power Pivot超級數據透視表界面,然后按下圖設置Power Pivot超級數據透視表布局,即可在Power Pivot超級數據透視表中得到圖書子類的銷售總冊數與其所屬圖書大類的銷售總冊數的比值。
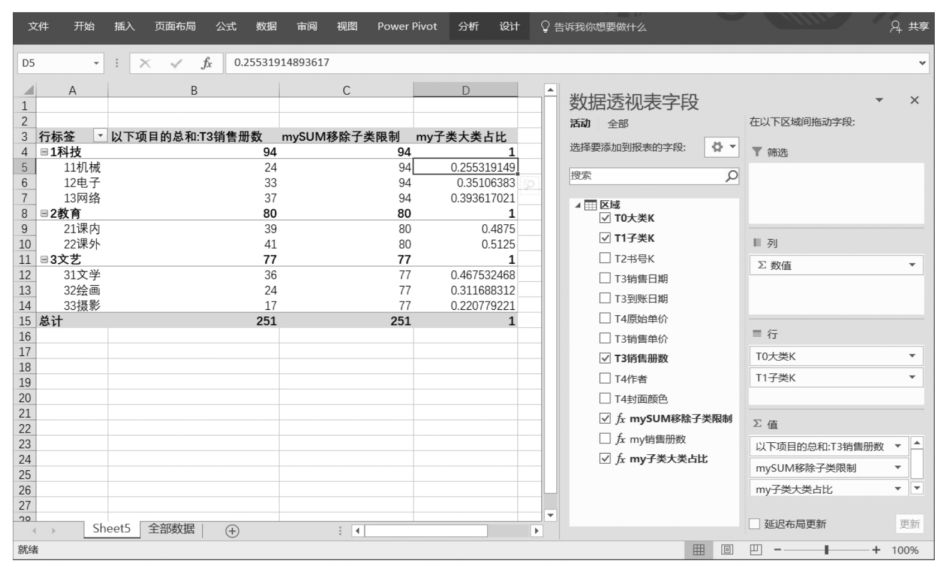
修改Power Pivot超級數據透視表布局,在Power Pivot行標題中移除“T0大類K”字段,得到新的Power Pivot超級數據透視表如下圖所示。
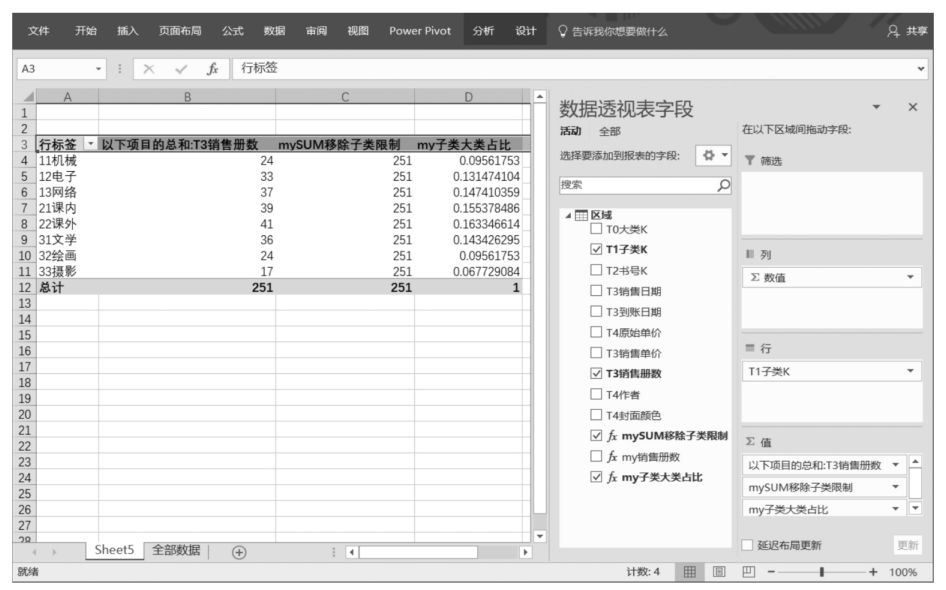
現在,在數據透視表篩選環境中移除了圖書大類的篩選限制,只剩下圖書子類的篩選限制,同時DAX表達式“mySUM移除子類限制”用ALL('區域'[T1子類K])移除了圖書子類的篩選限制,相當于在沒有任何篩選限制的情況下計算圖書銷售總冊數,因此,我們看到,在“mySUM移除子類限制”字段的每個單元格中顯示的都是圖書銷售總冊數251。
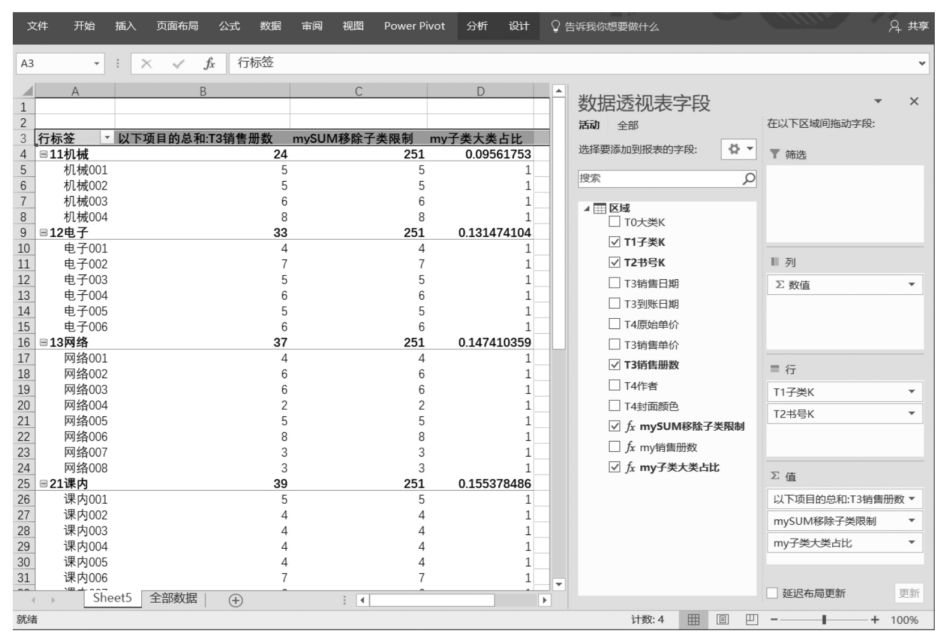
現在,再次改變Power Pivot超級數據透視表布局,將“T2書號K”字段拖曳至Power Pivot行標題中,再次觀察“mySUM移除子類限制”字段的所有單元格,這次,盡管行標題“T1子類K”對該字段的篩選限制已經被ALL()函數移除了,但是,由于在數據透視表篩選環境中增加了行標題“T2書號K”對該字段的篩選限制,因此,得到如下圖所示的Power Pivot數據透視分析結果。
2.ALL()函數的參數是一個表
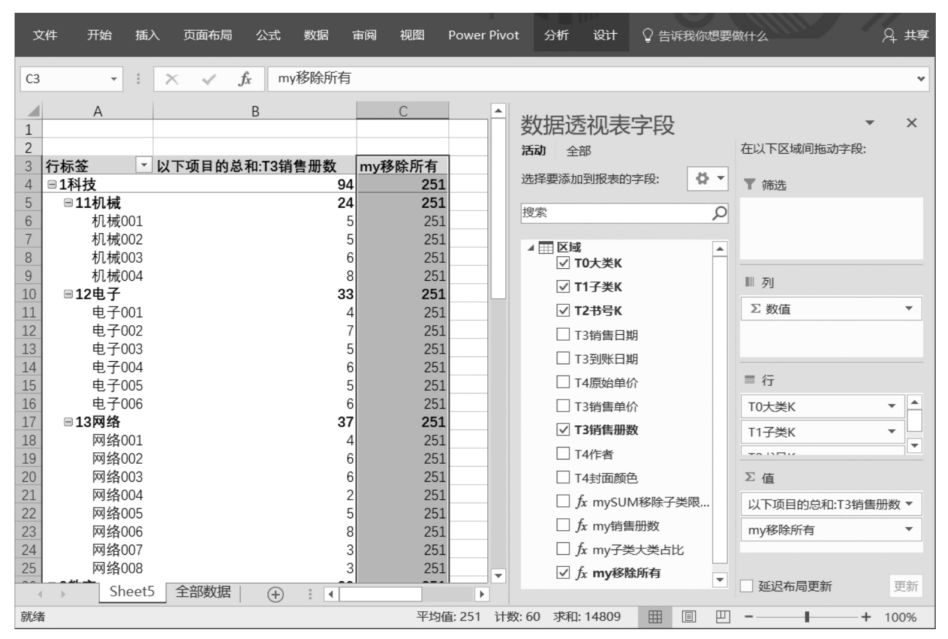
除了用表中的一列作為ALL()函數的參數,還可以用表作為ALL()函數的參數。如果ALL()函數的參數是一個表,那么它會在數據透視表篩選環境中移除指定表中所有列的篩選限制,如下面的DAX表達式:

上述DAX表達式可以在數據透視表篩選環境中移除“區域”表中所有列的篩選限制。在本案例中,Power Pivot數據模型中只有一個表,即DAX表達式“my移除所有”移除了數據透視表篩選環境中的所有篩選限制,因此,無論Power Pivot的行標題和列標題的布局如何變化,在數據透視表值區域的“my移除所有”字段中,得到的都是整個表中所有圖書的銷售總冊數251。
2.4.2 ALL()函數與ALLEXCEPT()函數
在DAX中有一個與ALL()函數對應的函數,即ALLEXCEPT()函數。我們可以認為ALLEXCEPT()函數是為了在特定應用場景中簡化ALL()函數而設計的。
如果在數據透視表篩選環境中需要使用ALL()函數移除篩選限制的字段比較多,使用類似ALL([字段1],[字段2],[字段3]...)的語法比較麻煩,那么可以使用ALLEXCEPT()函數實現。ALLEXCEPT()函數的語法格式如下:

ALLEXCEPT()函數的功能:在數據透視表篩選環境中,在ALLEXCEPT()函數第一個參數指定的表中,第二個參數指定的字段的篩選限制不會被移除,在同一個表中沒有在ALLEXCEPT()函數中列出的字段的篩選限制會被移除。
觀察下面的DAX表達式:


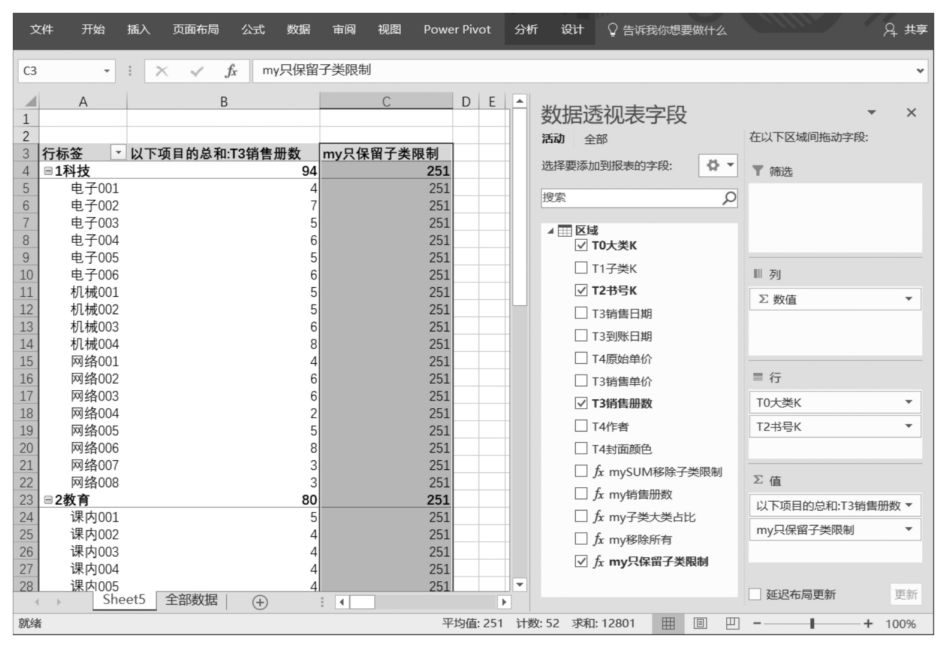
上述DAX表達式的作用:在數據透視表篩選環境中,只保留“區域”表中“T1子類K”字段的篩選限制,移除該表中其他字段在數據透視表篩選環境中的篩選限制。
如果將該DAX表達式拖曳至Power Pivot超級數據透視表值區域中,那么DAX表達式“my只保留子類限制”的計算結果是所有圖書銷售總冊數251,如下圖所示。
在英語單詞中,ALL的本意是“包含所有”,但是在DAX中,結合數據透視表篩選環境,以及ALL()函數和ALLEXCEPT()函數的功能,將ALL理解為“移除篩選限制”更合理。
2.4.3 CONCATENATEX()函數與VALUES()函數
下面介紹一個非常有用的函數,即CONCATENATEX()函數。CONCATENATEX()函數的功能是用指定的分隔符連接指定表中特定列中的內容,計算結果是一個長字符串。
在傳統Excel數據透視表的值區域中只能顯示數值,而不能顯示文本。在PowerPivot中,借助CONCATENATEX()函數,這個問題可以得到完美解決。
在英文中,CONCATENATE的含義是連接,在這個單詞后面加一個X,表示CONCATENATEX()函數是一個對表進行逐行處理的函數。CONCATENATEX()函數最簡單的語法格式如下:

下面結合實例講解該函數的用法。如果要知道在某個圖書大類或圖書子類下銷售了哪些圖書,那么可以使用如下DAX表達式:

將上述DAX表達式拖曳至Power Pivot超級數據透視表值區域中,得到的計算結果如下圖所示。雖然這個數據透視表看起來很擁擠,但是它正確地得到了每個圖書大類下的每個圖書子類所銷售的圖書的名稱列表。
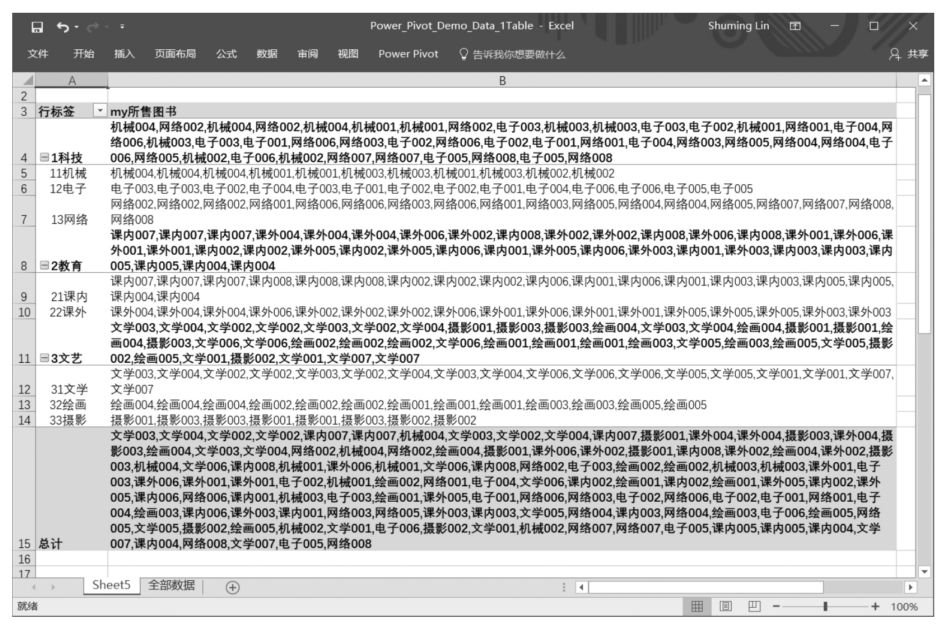
通過觀察發現,雖然上面的Power Pivot初步滿足了我們的需求,但是缺點也相當明顯:圖書名稱重復且排序雜亂。如果希望重復銷售的圖書名稱只出現一次,并且圖書名稱能夠按照特定的順序排列,那么單靠CONCATENATEX()函數是不夠用的。下面介紹一個新的DAX函數,即VALUES()函數。
VALUES()函數的功能是壓縮重復,參數一般為表中的一列,其計算結果是一個基于該列、沒有重復值、只有一列的表。使用VALUES()函數優化后的DAX表達式如下:

在Power Pivot數據模型管理界面中輸入上述DAX表達式,在返回Power Pivot超級數據透視表界面后,將該DAX表達式拖曳至Power Pivot超級數據透視表值區域中,得到的計算結果如下圖所示。
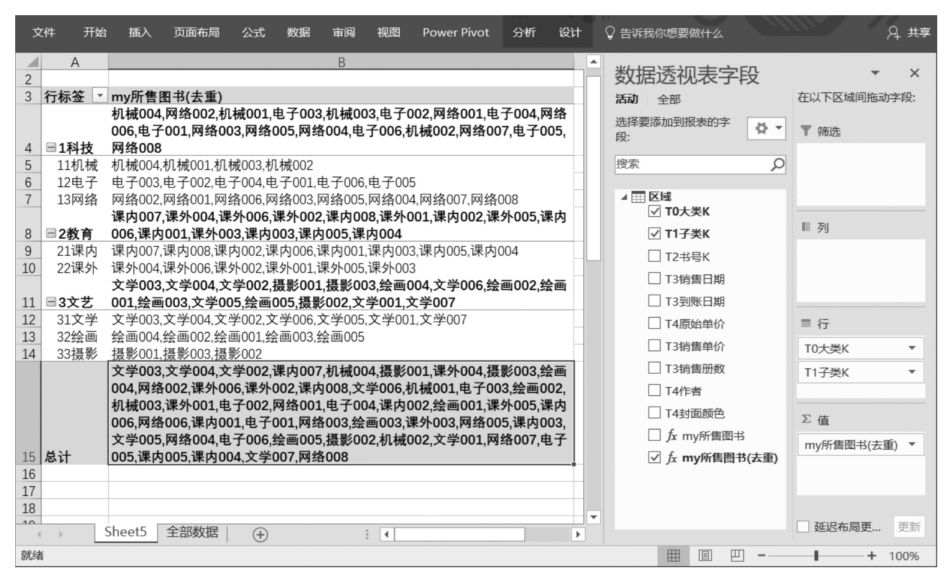
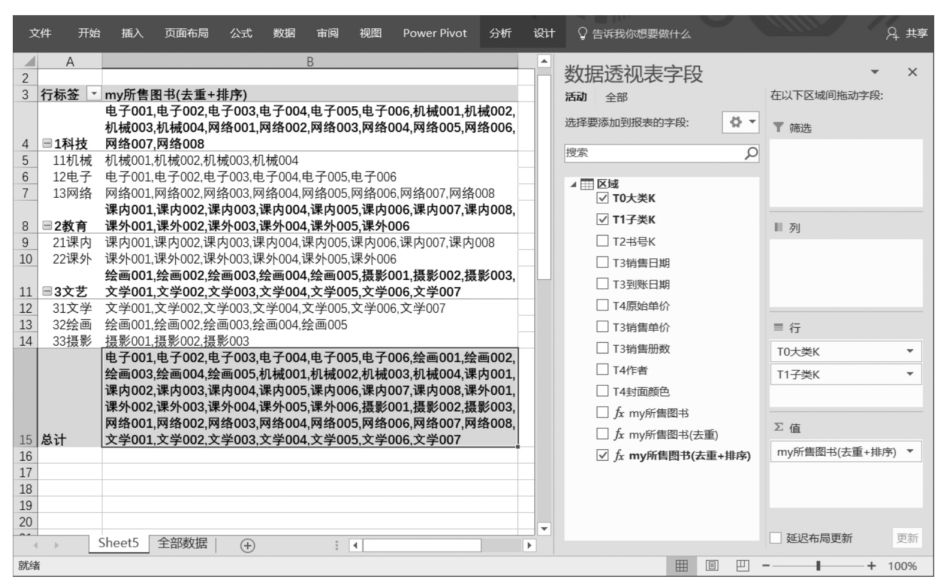
可以看到,重復值確實去掉了,但結果尚未按照圖書名稱排序,還需要繼續優化。其實,排序是CONCATENATEX()函數自帶的一個功能。在本案例中,在CONCATENATEX()函數中指定排序的字段和排序的順序,即可實現優化。優化后的DAX表達式如下:

這里的最后兩個參數,'區域'[T2書號K]表示按照該列進行排序,ASC表示按照升序排序。最終的計算結果如下圖所示。
2.4.4 篩選函數——FILTER()函數
在介紹CALCULATE()函數時曾經提到,CALCULATE()函數有兩個特點,第一個是它能夠識別當前的數據透視表篩選環境,第二個是它能夠借助篩選器參數修改當前數據透視表篩選環境。
針對CALCULATE()函數的第二個特點,什么內容可以作為CALCULATE()函數的篩選器參數呢?答案是既可以是DAX函數,又可以是DAX表達式。這里我們介紹一種最常見的情況:用FILTER()函數作為CALCULATE()函數的篩選器參數。
FILTER()函數能夠對指定的表進行篩選,這個指定的表既可以是Power Pivot數據模型中實際存在的實體表,也可以是由其他DAX表達式計算生成的表。FILTER()函數的計算結果是一個經過FILTER()函數篩選后的新表。FILTER()函數的語法格式如下:


這里的“表或計算結果為表的DAX表達式”是指要篩選的表或計算結果是表的DAX表達式,而“篩選條件”是指要對FILTER()函數指定表中的每行進行測試的判斷條件。
FILTER()函數是一個逐行處理函數。逐行處理函數的特點如下:能夠對其第一個參數所指定的表進行逐行判斷或計算,按行生成中間結果,并且依據這些中間結果再次進行匯總計算,從而得到函數的最終計算結果。
對于FILTER()函數,其內部運算邏輯如下:
FILTER()函數對第一個參數所指定的表中的每行,都會用第二個參數所設置的篩選條件進行測試,將滿足測試條件的行留下來,將不滿足測試條件的行舍棄。這樣,FILTER()函數一行一行地測試下來,會得到一個新的數據表,這個數據表中的每行都滿足第二個參數所設置的測試條件。
使用如下DAX表達式統計在數據源中不同的圖書分類下,“T4封面顏色”字段值為“藍”的記錄各有多少條(藍色封面的記錄在數據源中出現的次數)。

在Power Pivot超級數據透視表中,匯總計算的最終結果要以數值的形式在Power Pivot超級數據透視表值區域中呈現。我們知道,Power Pivot超級數據透視表值區域中的單元格中只能顯示數字和文本,不能顯示表。而FILTER()函數的計算結果是一個表,因此為了能在Power Pivot超級數據透視表值區域中看到FILTER()函數的計算結果,只能借助其他DAX函數,將表內容匯總成一個數值,從而驗證FILTER()函數的計算結果是否正確。在本案例中,我們使用COUNTROWS()函數來計算FILTER()函數的計算結果的行數,從而驗證FILTER()函數的計算結果是否正確。
在Power Pivot數據模型管理界面的DAX表達式編輯區中的單元格中輸入上述DAX表達式,如下圖所示。
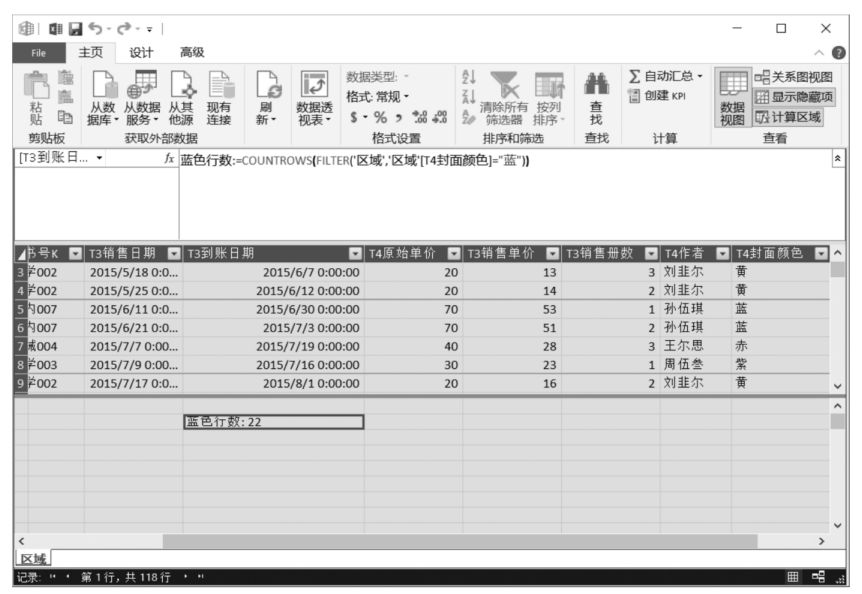
返回Power Pivot超級數據透視表界面,將DAX表達式“藍色行數”拖曳至數據透視表值區域中,即可看到在數據源中每種圖書類別下藍色封面的記錄條數,如下圖所示。注意,這里計算的是在數據源中滿足'區域'[T4封面顏色]="藍"的記錄條數,不是圖書銷售冊數。
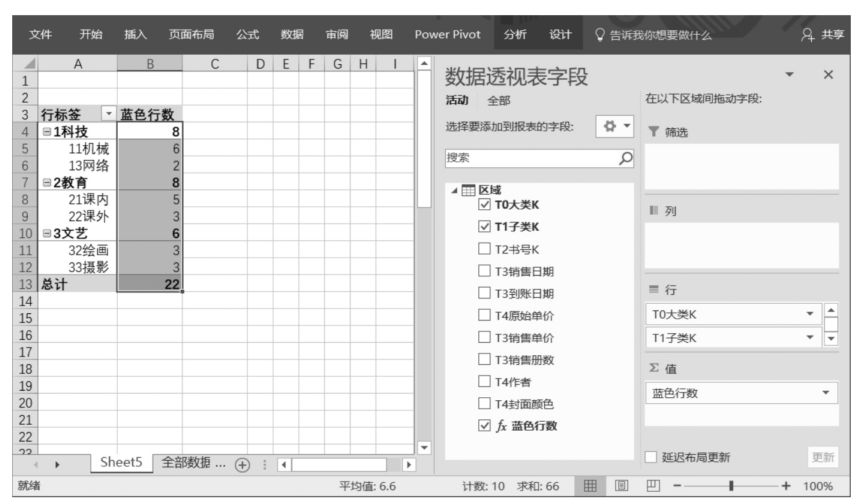
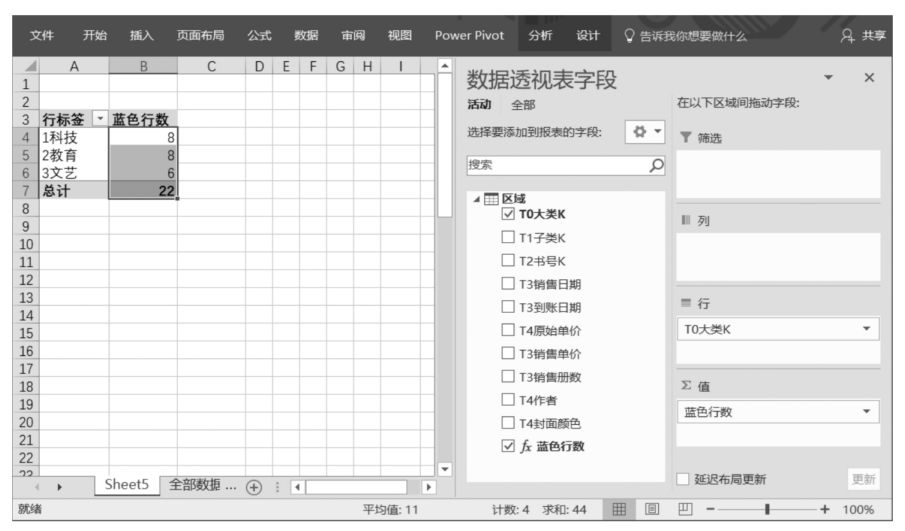
此外,可以按照下圖更改Power Pivot超級數據透視表布局。無論是上圖還是下圖,該DAX表達式都正確地計算出了滿足數據透視表篩選環境的結果。如果對這個結果還有懷疑,那么可以到數據源中進行驗證。
2.4.5 CALCULATE()函數與FILTER()函數
上節提到,FILTER()函數是一個能夠對第一個參數所指定的表進行逐行處理的函數。在DAX函數中,能夠對表進行逐行處理的函數有多個,在后面的章節中將引入更多逐行處理函數。在初步了解CALCULATE()函數、FILTER()函數和ALL()函數之后,本書開始研究稍微復雜的案例:在當前數據透視表篩選環境下,計算當前圖書子類的銷售冊數與“12電子”圖書子類的銷售冊數的比值。
為了完成本案例的任務,首先需要計算在當前數據透視表篩選環境下“12電子”圖書子類的銷售冊數。完成這個子任務的DAX表達式如下:

將上述DAX表達式拖曳至Power Pivot超級數據透視表值區域中,該DAX表達式的計算結果如下圖所示。
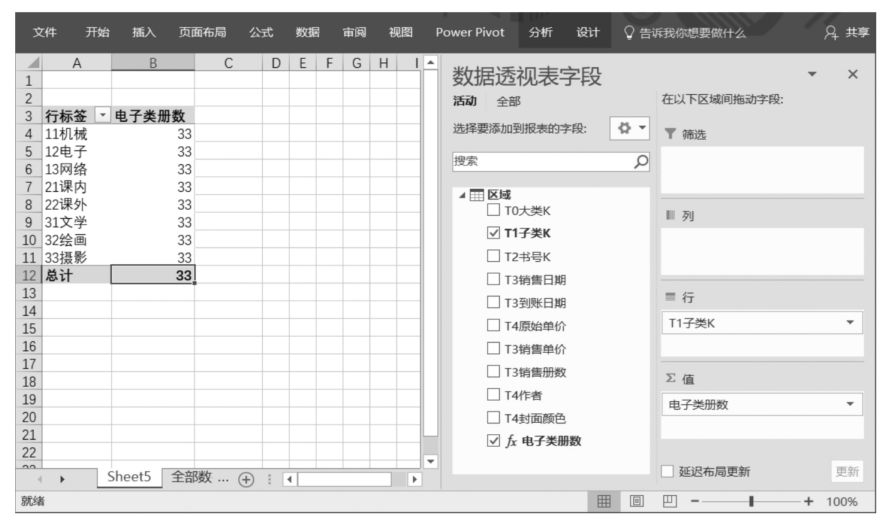
在上圖中,數據透視表篩選環境中只有“T1子類K”行標題的篩選限制,在DAX表達式“電子類冊數”中,我們用到了CALCULATE()函數。
我們反復強調,CALCULATE()函數具有(借助其篩選器參數)修改其當前數據透視表篩選環境的能力。在本案例中,篩選器參數使用的是FILTER()函數與ALL()函數嵌套的DAX表達式:

在介紹FILTER()函數時,我們了解到,該函數的第一個參數必須是一個表或計算結果為表的DAX表達式。在上述DAX表達式中,FILTER()函數的第一個參數是一個能夠生成表的DAX表達式:ALL('區域'[T1子類K])。
ALL('區域'[T1子類K])的計算結果是一個只有一列的表,這里ALL()函數的作用是移除數據透視表篩選環境中“T1子類K”字段對數據源的篩選限制,因此,在數據透視表篩選環境中,在沒有其他篩選限制的情況下,ALL('區域'[T1子類K])得到的應該是一個包含所有圖書子類的數據源子集。
接下來,使用FILTER()函數對ALL('區域'[T1子類K])的計算結果進行進一步加工:

在上述DAX表達式中,使用FILTER()函數對ALL()函數計算得到的表進行逐行測試,只留下滿足'區域'[T1子類K]="12電子"的記錄。
最后,借助CALCULATE()函數,在數據透視表篩選環境和篩選器參數(用于修改數據透視表篩選環境)的綜合作用下,對“T3銷售冊數”字段進行求和,即可得到在當前數據透視表布局下,每個圖書子類對應的值都是“12電子”圖書子類的銷售冊數。
以DAX表達式“電子類冊數”為分母,以當前圖書子類的銷售冊數為分子,最終的DAX表達式如下:

上述DAX表達式的計算結果如下圖所示。
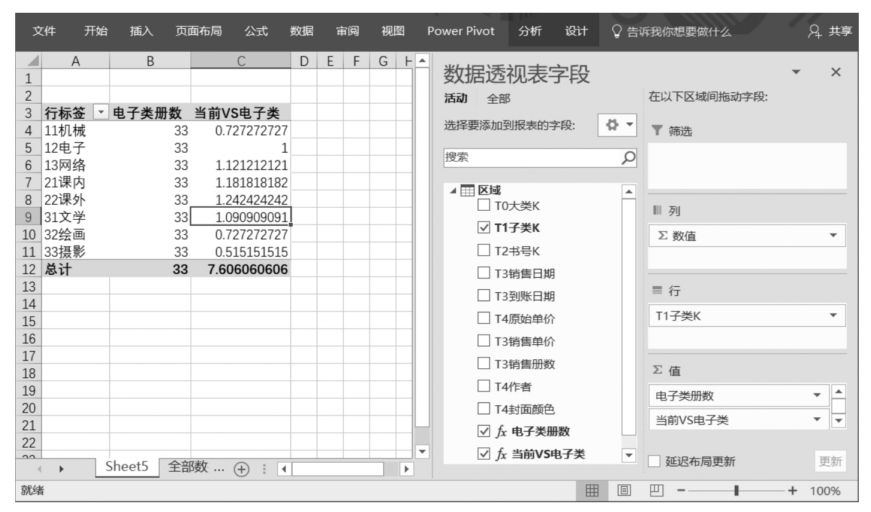
在上述DAX表達式中,FILTER()函數與ALL()函數嵌套組成的DAX表達式如下:

可以簡寫成如下格式:

因此,DAX表達式:


可以簡寫成如下格式:

綜上所述,類似如下格式的DAX表達式:
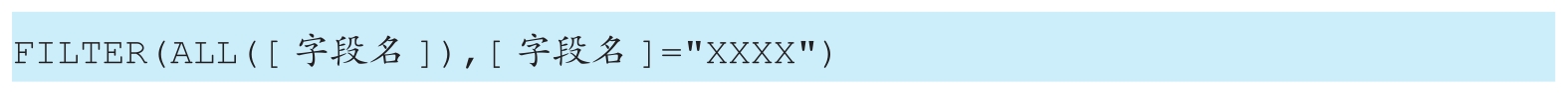
可以簡寫成如下格式:

事實上,上述DAX表達式還不是很完美。例如,如果修改Power Pivot超級數據透視表布局,將“T0大類K”字段也加入數據透視表行標題中,那么除了“1科技”圖書大類外,其他圖書大類下的“當前VS電子類”字段的值都是“#NUM!”,如下圖所示。
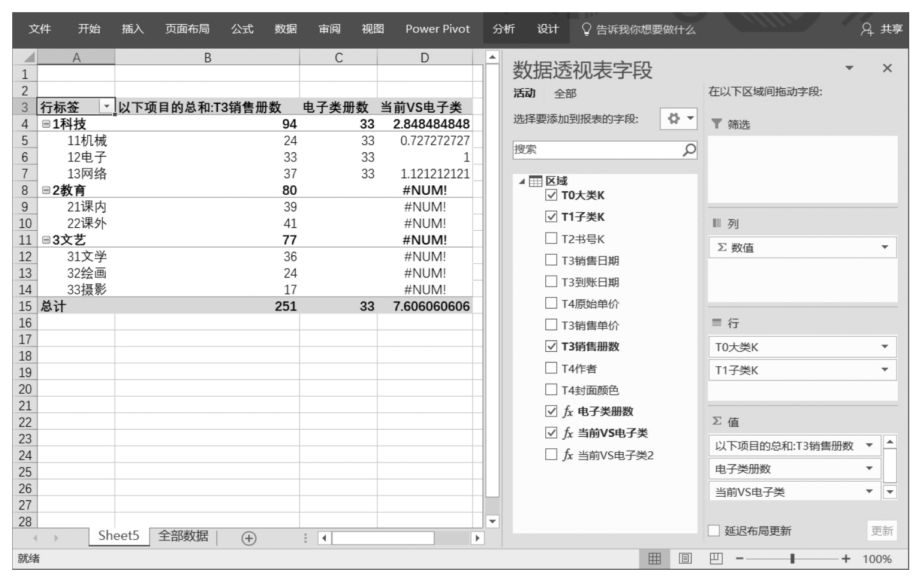
之所以出現上述問題,是因為雖然使用ALL('區域'[T1子類K])移除了數據透視表篩選環境中“T1子類K”字段的篩選限制,但也只是移除了這一個篩選限制,數據透視表篩選環境中的其他篩選限制(無論是原有的還是新添加的)并不受影響。因此,在將“T0大類K”字段拖曳至數據透視表篩選環境中時,“T0大類K”字段的篩選限制仍然起作用,這時ALL('區域'[T1子類K])就變成了在圖書大類限制下的ALL()函數,但是,除了“1科技”圖書大類外,“2教育”和“3文藝”圖書大類下根本沒有“12電子”圖書子類,因此FILTER(ALL('區域'[T1子類K]),'區域'[T1子類K]="12電子")的計算結果為空,這就是出現“#NUM!”的原因。
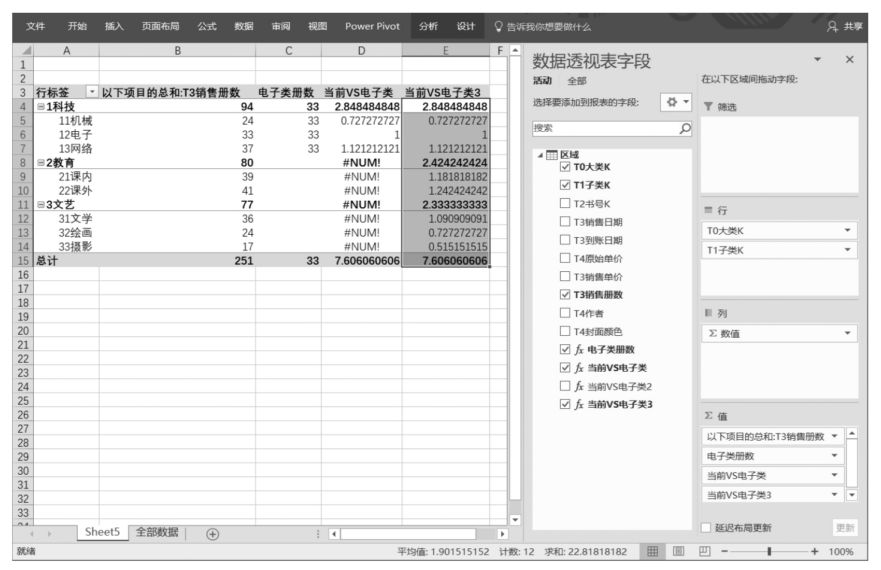
為了解決這個問題,我們將ALL('區域'[T1子類K])修改成ALL('區域'),在數據透視表篩選環境中取消了所有字段的篩選限制,這樣,無論將哪個字段拖曳至數據透視表篩選環境中,對DAX表達式“當前VS電子類3”分母部分的DAX表達式都起不到篩選作用了,但對分子部分的DAX表達式SUM('區域'[T3銷售冊數])的篩選作用依然存在,因為它沒有從數據透視表篩選環境中移除任何篩選限制。能夠完美地完成本案例任務的DAX表達式如下:

上述DAX表達式的計算結果如下圖所示。
2.4.6 DAX表達式與Power Pivot超級數據透視表布局
本節講解DAX表達式與Power Pivot超級數據透視表布局之間的關系。
設計一個DAX表達式,并且將其拖曳至Power Pivot超級數據透視表值區域中,如果改變Power Pivot超級數據透視表布局,在數據透視表篩選環境中增加或減少篩選限制,那么該DAX表達式的計算結果會隨著Power Pivot超級數據透視表布局的變化而重新計算,重新計算的結果也許會出現一些看似難以理解的變化。以前面講過的一個DAX表達式為例:

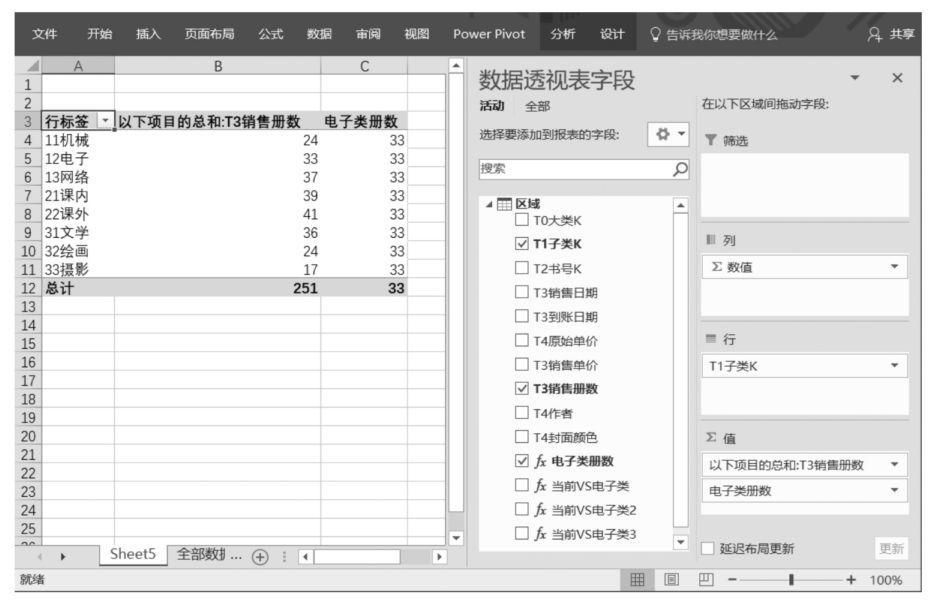
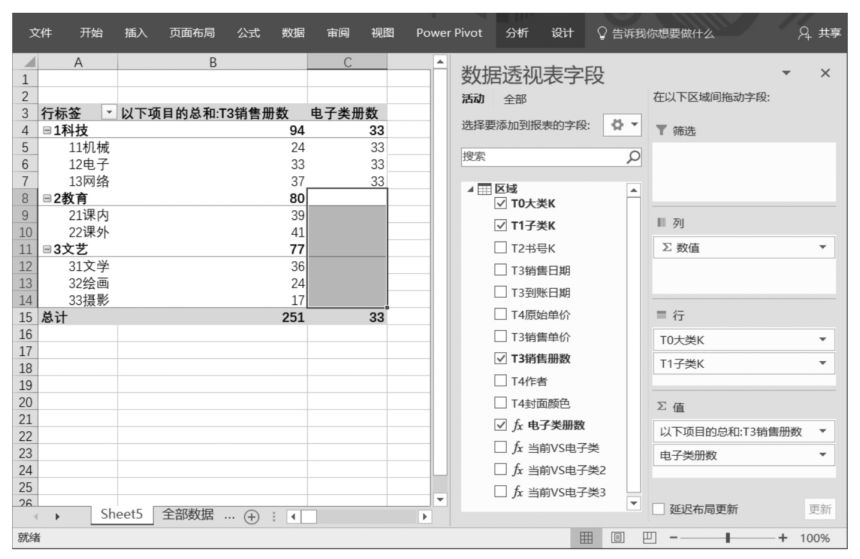
Power Pivot超級數據透視表布局如下圖所示。觀察下圖可知,Power Pivot超級數據透視表值區域中有兩個DAX表達式,其中DAX表達式“以下項目的總和:T3銷售冊數”是直接將數據源中的“T3銷售冊數”字段拖曳至Power Pivot超級數據透視表值區域中得到的(數字字段默認為求和運算)。另一個DAX表達式“電子類冊數”就是我們設計的DAX表達式。當數據透視表只有行標題,并且行標題是“T1子類K”字段時,DAX表達式“電子類冊數”似乎很完美。
但是,當在數據透視表行標題中加入“T0大類K”字段時,DAX表達式“電子類冊數”似乎就不那么完美了,“電子類冊數”字段中竟然出現了空值,如下圖所示。
關于這個問題的解釋上一節已有涉及,為了更加透徹地理解Power Pivot,本節對該問題進行深入探討。為了便于對比分析,我們再次展示DAX表達式“電子類冊數”:

在DAX表達式“電子類冊數”中,作為CALCULATE()函數篩選器參數的FILTER(ALL('區域'[T1子類K]),'區域'[T1子類K]="12電子")用ALL()函數移除的只是數據透視表篩選環境中的篩選限制'區域'[T1子類K],對其他字段的篩選限制沒有影響。這時,這些包含在ALL()函數中的字段一旦被拖曳至數據透視表篩選環境中,它在數據透視表篩選環境中的作用就會顯現出來。例如,當Power Pivot超級數據透視表行標題是“1科技”圖書大類的篩選限制時,會得到一個包含圖書子類“11機械”、“12電子”和“13網絡”的數據源子集。用FILTER()函數的第一個參數ALL('區域'[T1子類K])移除了'區域'[T1子類K]的篩選限制,再用FILTER()函數的第二個參數'區域'[T1子類K]="12電子"對“1科技”圖書大類下的數據源子集進行進一步篩選,得到一個圖書子類只有“12電子”的更小的數據源子集,最后,用CALCULATE()函數的第一個參數(匯總參數)SUM([T3銷售冊數])對這個更小的數據源子集進行匯總計算。因此,在“1科技”圖書大類下,DAX表達式“電子類冊數”對應的數據透視表值區域中的單元格中有相同的數值33。
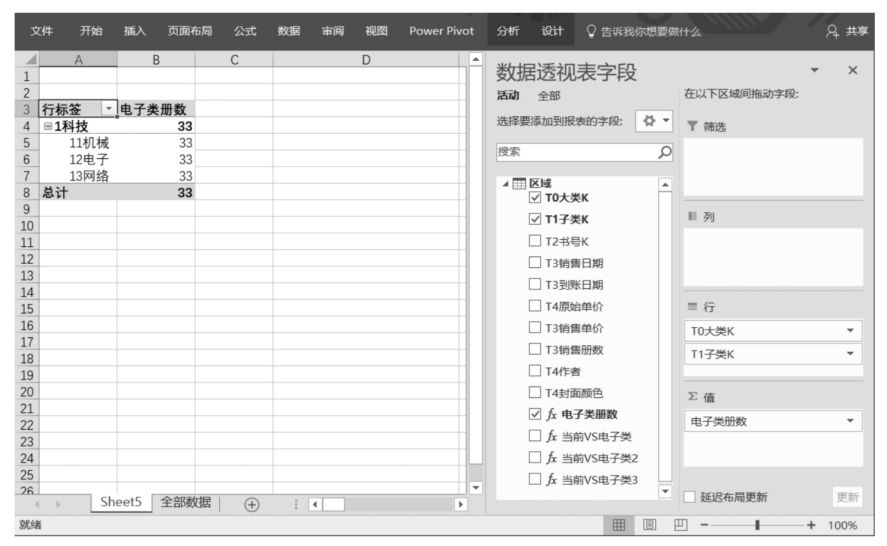
按照上述邏輯進行推演,在數據透視表篩選環境中圖書大類是“2教育”“3文藝”的篩選限制下,不可能得到包含“12電子”圖書子類的數據源子集,因此,在“2教育”“3文藝”圖書大類中,即使用FILTER()函數的第一個參數ALL('區域'[T1子類K])移除了'區域'[T1子類K]的篩選限制,也不可能得到包含“12電子”圖書子類的數據源子集(因為“12電子”圖書子類不屬于這兩個圖書大類),這時,用FILTER()函數的第二個參數'區域'[T1子類K]="12電子"對這個本來就不含“12電子”圖書子類的數據源子集進行進一步篩選,會得到一個沒有任何數據的空集。因此,在圖書大類是“2教育”“3文藝”的篩選限制下,DAX表達式“電子類冊數”對應的數據透視表值區域中的單元格中沒有任何數據(空值)。
現在,如果改變Power Pivot超級數據透視表布局,移除“T3銷售冊數”字段,那么沒有值的字段就不會在數據透視表中顯示了,如下圖所示。
2.4.7 關于CALCULATE()函數的類比
本節對學過的知識做一個總結,以便溫故知新。
對函數的學習,無論是DAX函數,還是Excel工作表函數,都要掌握以下四點:
● 參數個數;
● 數據類型;
● 使用順序;
● 函數計算結果的數據類型,即函數的計算結果是數字、文本、還是一個表。
這四點是學習函數的四要素。
特別地,對于部分DAX函數,必須增加一點,即了解它的運算邏輯。例如,它是否屬于逐行處理函數(如FILTER()函數),函數的參數如何參與運算。
關于函數參數參與運算的順序,以CALCULATE()函數為例,該函數先處理第二個參數(篩選器參數),然后處理第一個參數(匯總參數)。
我們可以將函數比作一臺加工設備。一臺加工設備需要按特定的投放順序投放一種或幾種不同的原料(相當于函數的參數),在經過機器加工處理后,產出成品和半成品。成品相當于函數的最終計算結果,半成品則需要用另一種設備繼續加工為成品,而這種以半成品為原料,在另一臺設備上繼續加工的情況就相當于函數嵌套概念。
以家里的豆漿機為例,這臺豆漿機就相當于一個DAX函數。豆漿機(函數)需要的原料是豆子和水,豆子和水相當于函數的參數。豆漿機加工產出的產品是生豆漿,生豆漿相當于函數的計算結果。豆漿機用豆子和水作為參數的DAX函數的語法格式如下:

該DAX函數的返回值為生豆漿。
如果豆漿機的使用說明書要求,在使用這臺豆漿機時,先放豆子,再放水,投放順序不能顛倒,那么該要求對應到DAX函數的意思就是,函數的參數必須嚴格放在其預先定義的位置,順序不可顛倒,否則函數就有可能計算錯誤。這里的豆漿機使用說明書就相當于DAX函數的幫助文檔。
此外,在使用豆漿機時,不能給豆漿機加錯原料(參數類型不能用錯)。你不能這樣使用豆漿機:

如果函數某個參數位置處需要一個數字類型的參數,你卻放置了一個文本數據,那么函數通常會報錯,不會得到正確的計算結果。
有些DAX函數有可選參數,類似于豆漿機可以根據個人需要增加一些附加原料。例如,喜歡甜味的豆漿,可以這樣:

至于一個函數是否可以使用可選參數,以及可選參數的類型,我們必須查看DAX函數的幫助文檔來確定。
DAX函數的計算結果既可以作為最終結果,也可以作為其他DAX函數的參數。正如豆漿機的產品(生豆漿)可以作為最終產品,也可以繼續加工,用電熱杯煮開作為熟豆漿飲用。如果電熱杯也是一個DAX函數,那么該函數的語法格式如下:

這種格式就是函數嵌套。
2.4.8 返回表的CALCULATETABLE()函數
在介紹CALCULATETABLE()函數之前,讓我們先回顧一下CALCULATE()函數,這是DAX函數中最重要的一個函數。CALCULATE()函數一般有兩個參數,第一個是起匯總作用的DAX表達式(匯總參數),第二個是對數據透視表篩選環境進行修改的DAX表達式(篩選器參數),這兩個參數順序不能顛倒。對于CALCULATE()函數,我們還需要注意它的內部運算邏輯:
CALCULATE()函數在運算時,先執行第二個參數,即先對數據透視表的當前數據透視表篩選環境進行修改,然后在基于修改了的數據透視表篩選環境下,進行由其第一個參數指定的匯總計算。需要注意的是,這里所說的對數據透視表篩選環境的修改,只在CALCULATE()函數的運算過程中有效。
CALCULATETABLE()函數是CALCULATE()函數的兄弟函數,用法和CALCULATE()函數基本相同,不同的是,CALCULATE()函數的第一個參數的計算結果是一個匯總值,而CALCULATETABLE()函數的第一個參數的計算結果是一個表,這也是CALCULATETABLE()函數名稱的由來(CALCULATETABLE()函數名稱的拼寫為CALCULATE+TABLE)。CALCULATETABLE()函數的語法格式如下:

將CALCULATETABLE()函數比作一臺加工設備,這臺設備需要兩種原料,一種是修改當前數據透視表篩選環境的DAX表達式(它的第二個參數,即篩選器參數),另一種是基于修改后的數據透視表篩選環境進行匯總計算的DAX表達式(它的第一個參數,即匯總參數)。這兩種原料(參數)的投放順序為,修改當前數據透視表篩選環境的DAX表達式(篩選器參數)必須放在第二個位置,基于修改后的數據透視表篩選環境進行匯總計算且計算結果為表的DAX表達式(匯總參數)必須放在第一個位置。一定要在函數的正確位置放置正確的參數,否則會導致函數不工作或函數計算結果錯誤等問題。
之所以先介紹CALCULATETABLE()函數的第二個參數,是因為CALCULATETABLE()函數與CALCULATE()函數一樣,其內部運算邏輯都是先執行第二個參數,再執行第一個參數。
CALCULATETABLE()函數的計算結果是一個表,這個表既可以作為最終結果,又可以作為下一個DAX函數的參數,但前提是下一個DAX函數需要這種表數據類型的參數。
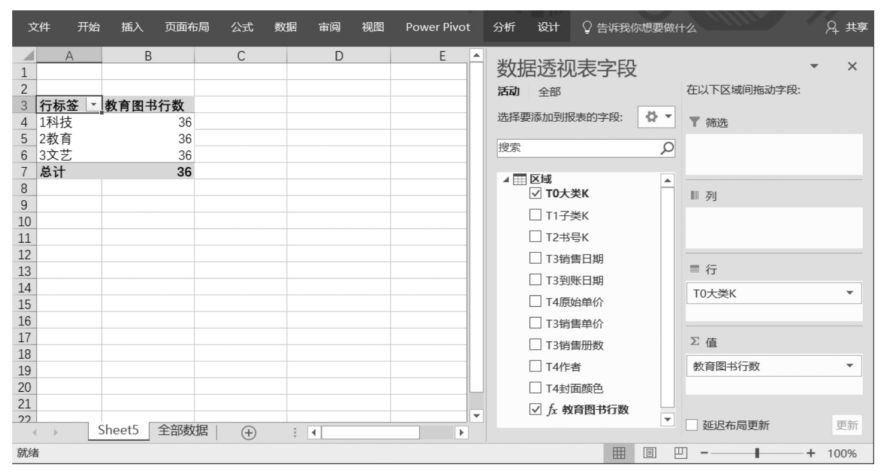
觀察下面的DAX表達式,該DAX表達式計算的是“2教育”圖書大類的銷售發生次數(假設數據源中的一條記錄表示銷售發生一次)。

在Power Pivot數據模型管理界面的DAX表達式編輯區中的單元格中輸入上述DAX表達式,并且將該DAX表達式字段“教育圖書行數”拖曳至Power Pivot超級數據透視表值區域中,然后調整Power Pivot超級數據透視表布局,如下圖所示。這時我們看到,在“教育圖書行數”字段中,每個圖書大類對應的值都為36。關于這個結果,請自行到數據源中驗證。注意,這里算出來的結果不是冊數,而是數據源中滿足DAX表達式計算結果的記錄的條數。
前面在講解FILTER()函數時提到過,類似FILTER(ALL([字段名]),[字段名]="XXXX")的DAX表達式可以直接寫成[字段名]="XXXX",因此,上述DAX表達式可以寫成更簡短的格式:

注意,之所以在CALCULATETABLE()函數外面包裹一個COUNTROWS()函數,是因為Power Pivot超級數據透視表值區域中的單元格中只能存放數值,而CALCULATETABLE()函數的計算結果是一個表,是無法在Power Pivot超級數據透視表值區域中的單元格中呈現的。因此,這里用COUNTROWS()函數計算出CALCULATETABLE()函數計算結果的行數。
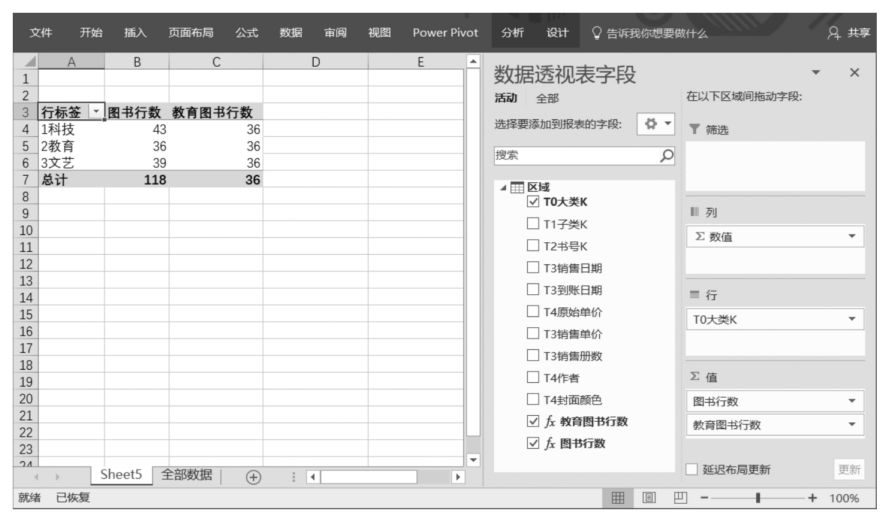
我們知道,CALCULATE()函數可以只有一個參數,同樣地,CALCULATETABLE()函數也可以只有一個參數。例如,計算在當前數據透視表篩選環境下圖書銷售發生的次數(數據源中銷售記錄的條數),其DAX表達式如下:

對應的Power Pivot超級數據透視表布局如下圖所示。
2.4.9 逐行處理匯總函數SUMX()
前面曾經說過,FILTER()函數是一個逐行處理函數。逐行處理函數的內部運算邏輯:對第一個參數所指定的表進行逐行判斷或計算,然后將逐行判斷或計算的結果以一個表或匯總成一個值的形式呈現。
在DAX函數中,這類具有逐行處理能力的函數有很多,并且這類函數的名稱通常以X結尾,如前面學過的CONCATENATEX()函數。CONCATENATEX()函數本質上是一個逐行處理函數,它的功能是逐行取出由其第一個參數指定表中特定列中的內容,然后將該列中的所有內容用指定的分隔符連接成一個長字符串。
本節我們再介紹一個非常有代表性的,并且非常重要的逐行處理函數——SUMX()函數。對于其他逐行處理函數,我們將在以后的章節中逐步引入。
大家可能已經注意到,前面介紹的DAX表達式都是用于計算圖書銷售冊數的,但在現實中,數據分析通常以計算銷售金額為主。在本書的數據源中,并沒有直接給出圖書的銷售金額。在Power Pivot中,計算圖書銷售金額有兩種方法,一種是在Power Pivot數據模型管理界面中添加新的計算列,另一種是設計DAX表達式。
用添加計算列的方法計算圖書銷售金額非常簡單,進入Power Pivot數據模型管理界面,在數據表的最后一列任選一個單元格,在公式欄中輸入如下計算列公式:

然后雙擊列標題,將標題名稱修改為“銷售金額”,如下圖所示。
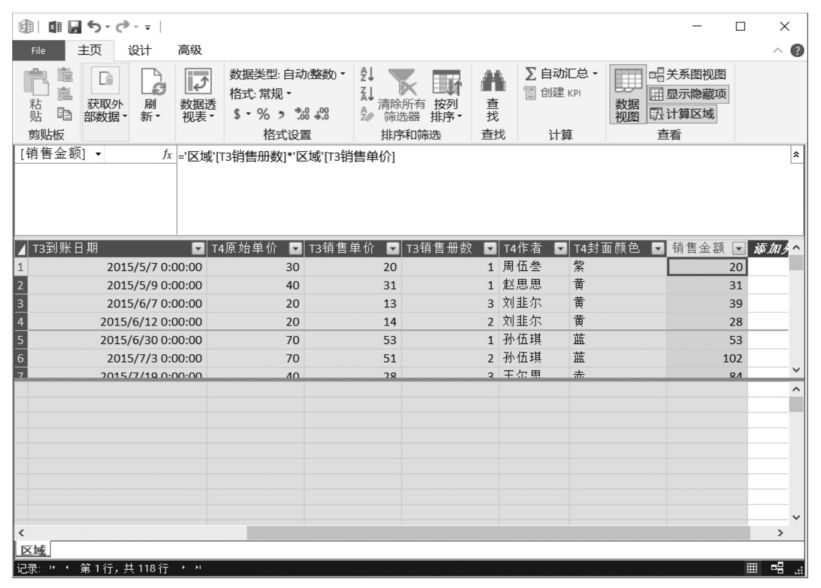
返回Power Pivot超級數據透視表界面,將剛剛添加的計算列字段拖曳至Power Pivot超級數據透視表值區域中,計算結果如下圖所示。
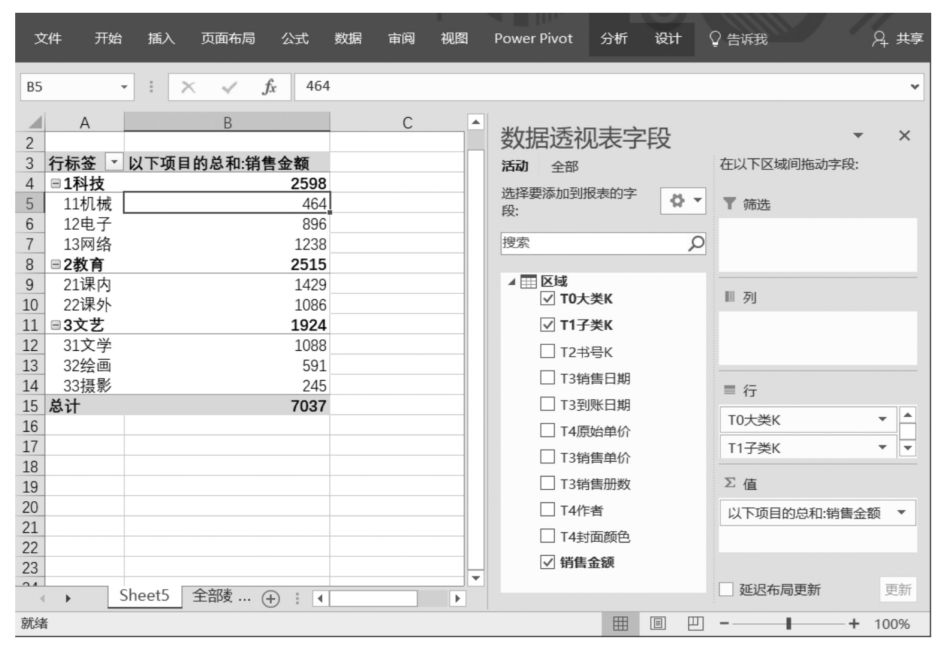
上述方法雖然能夠完成任務,但是Power Pivot設計人員建議盡量少使用計算列。他們認為,對于超大表來說,使用計算列會消耗較多的計算機軟硬件資源。為此,他們專門設計了逐行處理匯總函數SUMX(),將SUMX()函數應用于Power Pivot的DAX表達式中,可以實現同樣的計算功能。使用SUMX()函數計算圖書銷售金額的DAX表達式如下:

在Power Pivot數據模型管理界面的DAX表達式編輯區中的單元格中輸入上述DAX表達式,如下圖所示。
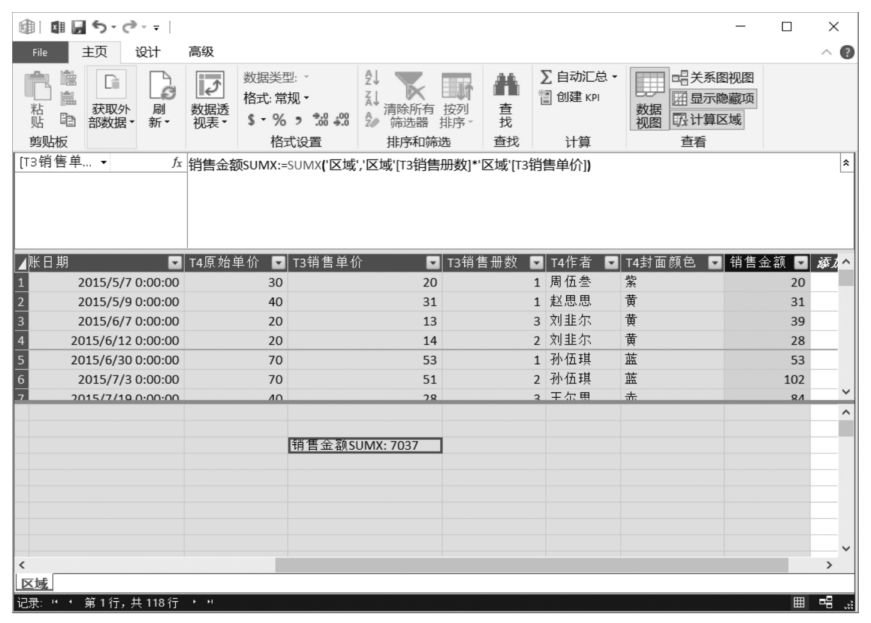
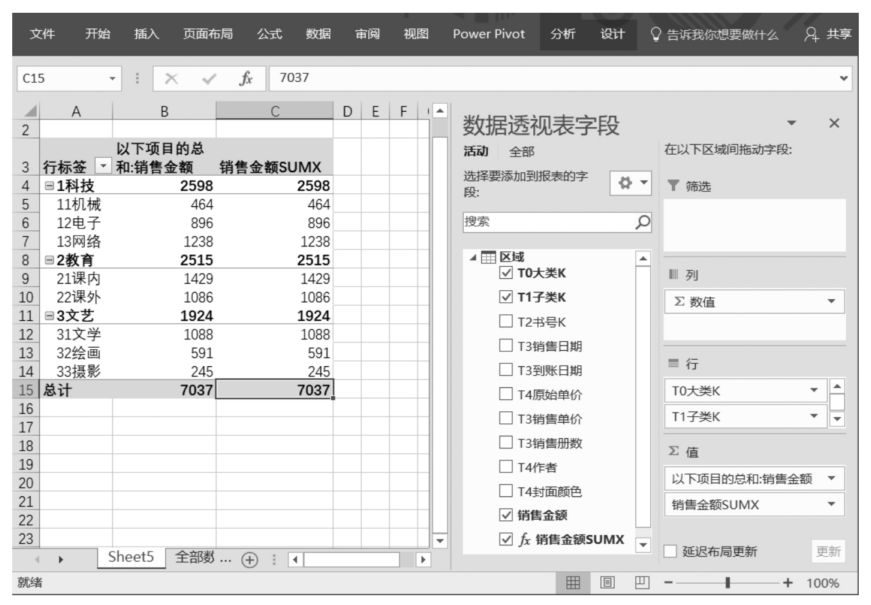
切換至Power Pivot超級數據透視表界面,將該DAX表達式拖曳至Power Pivot超級數據透視表值區域中,計算結果與采用計算列方法的計算結果是一致的,如下圖所示。
下面詳細介紹SUMX()函數的使用方法。SUMX()函數是Power Pivot中經常用到的一個函數,該函數的官方說明為,SUMX()函數返回表中“每行計算”的表達式之和,其語法格式如下:

針對SUMX()函數的官方解釋,需要強調以下兩點。
第一:SUMX()函數是一個逐行處理函數,它能夠對第一個參數指定的表中的每行進行逐行處理,每行的處理規則由它的第二個參數決定。理解SUMX()函數逐行處理的運算機制非常重要,這是SUMX()函數區別于非逐行處理函數的特征所在。
第二:SUMX()函數的內部運算邏輯我們是看不見的,我們看到的只是SUMX()函數的最終計算結果。也就是說SUMX()函數能夠將其第一個參數指定表的逐行處理結果累加起來,最后作為一個獨立的數值呈現給我們。
在講解CALCULATE()函數時曾經提到,當一個DAX表達式被拖曳至Power Pivot超級數據透視表值區域中時,Power Pivot會隱含地在DAX表達式外面包裹一個CALCULATE()函數,使之能夠識別其當前所處的數據透視表篩選環境。
針對本案例,雖然我們只在Power Pivot數據模型管理界面中輸入了一個非常簡單的DAX表達式:

但是,它卻完成了以下邏輯:對DAX表達式“銷售金額SUMX”所處的當前數據透視表篩選環境下的數據源子集中的每行,計算出'區域'[T3銷售冊數]*'區域'[T3銷售單價]的結果,并且將這些結果匯總成一個數值。
為了使大家加深對SUMX()函數的理解,我們再舉一個例子,順便復習一下前面學過的ALL()函數,同時引入一個超級簡單的算術函數——DEVIDE()函數。
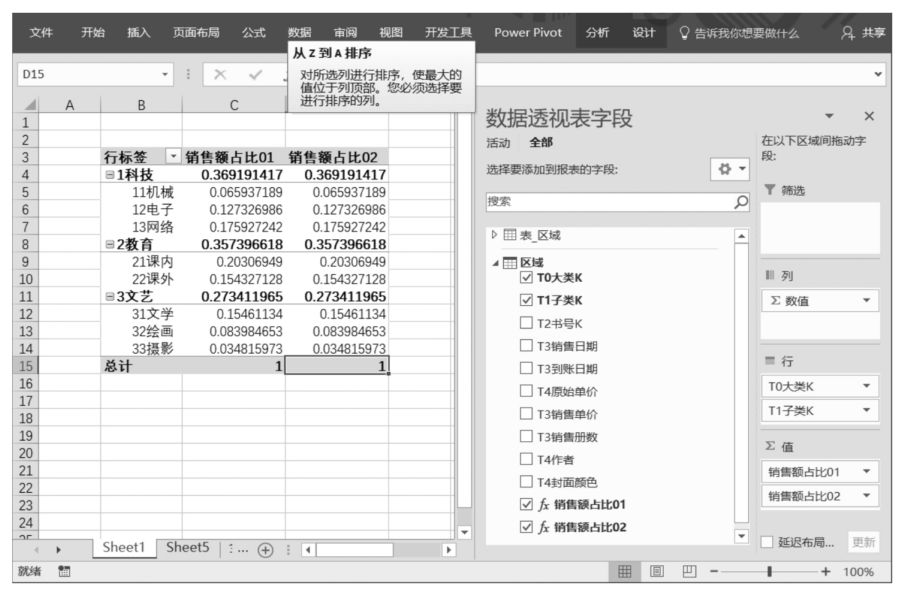
要計算每類圖書的銷售金額比較簡單,用SUMX()函數創建一個DAX表達式,將其拖曳至Power Pivot超級數據透視表值區域中即可。但是,如果要得到當前數據透視表篩選環境下的圖書銷售金額與圖書銷售總金額的比值,就需要借助ALL()函數了,其DAX表達式如下:

在DAX表達式中,一般使用DIVIDE()函數代替除號,DIVIDE()函數的語法格式如下:

使用DEVIDE()函數代替除號的特點:當除法的分母為0時,計算結果顯示為空,不會顯示錯誤符號。
將DAX表達式“銷售額占比01”中的除號用DEVIDE()函數代替后的DAX表達式如下:

DAX表達式“銷售額占比01”和DAX表達式“銷售額占比02”的計算結果如下圖所示。
- VMware虛擬化與云計算:vSphere運維卷
- AutoCAD 2019中文版從入門到精通
- ASP.NET jQuery Cookbook
- AutoCAD 2016中文版完全自學手冊
- Instant Testing with QUnit
- PowerPoint 2013從新手到高手(超值版)
- SPSS統計分析
- After Effects 影視后期特效:短視頻制作實戰寶典
- AutoCAD 2019中文版實戰從入門到精通
- SQL Server 2005數據挖掘與商業智能完全解決方案
- 剪映專業版:PC端短視頻制作(全彩慕課版)
- After Effects影視特效與電視欄目包裝實例精粹
- After Effects 動態圖形設計:入門技法與基礎創作
- Photoshop淘寶網店設計與裝修完全實例教程
- AutoCAD 2020中文版完全自學一本通