- 機器學習案例分析(基于Python語言)
- 王愷
- 2460字
- 2020-07-02 15:47:54
第1章 基礎知識
1.1 機器學習簡介
1.1.1 基本概念
機器學習(Machine Learning,ML)是人工智能的一個分支,它是一門多領域交叉學科,專門研究計算機怎樣模擬或實現人類的學習行為,涉及概率論、統計學、逼近論、凸分析、算法復雜度理論等多門學科。利用機器學習方法解決實際問題時,涉及模型結構設計、學習目標(也稱優化目標、目標函數或損失函數)設計、優化算法設計等方面的工作。機器學習的目標是根據已有數據(訓練數據,也稱訓練樣本)設計模型并學習模型參數,使得學習后的模型能夠在未知數據(測試數據,也稱測試樣本)上展現出較好的性能(具有較低的泛化誤差,或具有較強的泛化能力)。需要注意,在進行模型設計和參數學習時只能使用訓練數據,而不能使用任何測試數據。
機器學習模型可簡單表示為
y=f ( x;θ) (1.1)
其中,f是機器學習模型的數學表示(一個映射函數),x是模型的輸入,y是模型的輸出,θ是模型的參數。模型設計和參數學習過程,實際上就是根據訓練數據進行映射函數f的設計,并按預先定義的優化目標(如預測輸出與目標輸出之間的平方誤差)進行參數θ的學習。模型應用過程,實際上就是根據設計好的映射函數f及學習好的參數θ,對于一個數據通過模型給出其預測輸出。例如,對于2.2節將要介紹的鳶尾花分類問題,輸入數據x是由花萼長度、花萼寬度、花瓣長度和花瓣寬度組成的一個包含4個元素的特征向量(此時稱該數據的特征維度為4),而目標輸出數據t則是某個鳶尾花子類(山鳶尾、變色鳶尾或維吉尼亞鳶尾,通常用整數表示不同類別,如0、1、2等);通過設計模型及基于訓練數據的模型參數學習,使模型能夠根據輸入的測試數據x',得到預測輸出數據y',并且y'與目標輸出數據t'應盡可能接近。
在機器學習模型的設計中,需要避免兩種情況,即欠擬合和過擬合。如圖1-1所示,是欠擬合和過擬合的一個簡單示例。所謂欠擬合,是指所設計的機器學習模型過于簡單,無法表示數據中蘊含的復雜規律。出現欠擬合情況時,機器學習模型在訓練數據和測試數據上的性能相近,但均表現較差。所謂過擬合,是指所設計的機器學習模型過于復雜,其能夠完美地對訓練數據進行擬合,但在訓練過程中未使用的測試數據上表現則很差。出現過擬合情況時,機器學習模型在訓練數據上性能很好,但在測試數據上性能很差。無論是欠擬合,還是過擬合,都會使得模型在測試數據上表現出不好的性能(較高的泛化誤差,或較差的泛化能力),無法滿足實際應用需要。因此,如何設計復雜度適中的機器學習模型,使其具有較強的泛化能力(模型在測試集上有較好的表現),是機器學習中一個非常重要的問題。
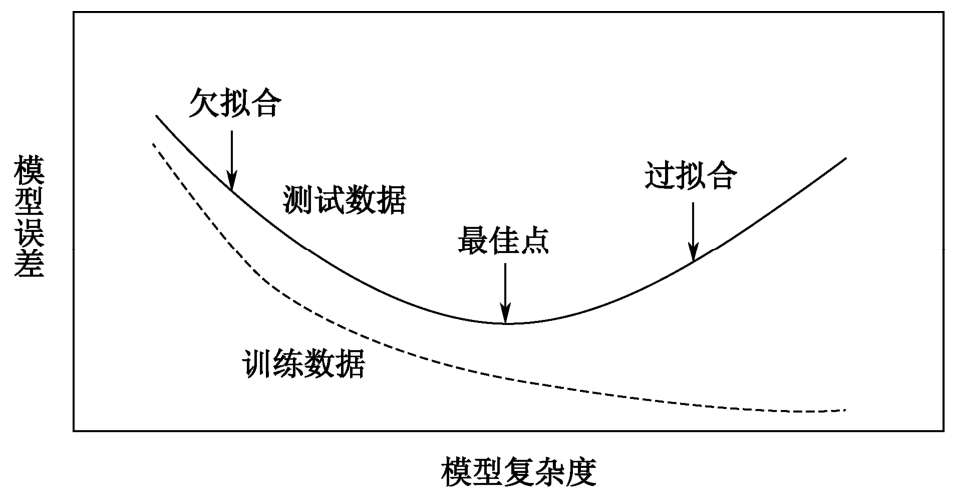
圖1-1 欠擬合和過擬合示例
為了能夠在不使用任何測試數據的情況下,設計出復雜度適中的機器學習模型,在實際應用中通常會將可用于訓練的數據進一步分為兩部分,分別是訓練數據和驗證數據。驗證數據僅用于預測模型的泛化能力,而不參與模型的參數學習過程。當可用于訓練的數據本身就很少時,通常采用K折交叉驗證方法來進行模型的設計。所謂K折交叉驗證,是指將可用于訓練的數據近似等分為K份,每次訓練時使用其中K-1份作為訓練數據進行模型參數學習,而沒有參與訓練的那一份作為驗證數據,用于進行模型泛化能力的預測。K份數據中的每一份都用作一次驗證數據后,K次實驗結果的平均值即該模型泛化能力的預測依據。
1.1.2 機器學習分類
從不同的角度,可以對機器學習方法進行不同的分類。從訓練數據是否包含目標值的角度,機器學習可以分為有監督學習方法和無監督學習方法;從目標值是不是連續值的角度,機器學習可以分為用于分類任務的方法和用于回歸任務的方法。這里簡單介紹一下這些方法的基本概念。
1.有監督學習
在有監督學習中,每一條訓練數據既包含特征向量x,也包含目標值t(目標值可以是單個數值,也可以是一個向量)。通過預先設計好的機器學習模型和優化目標函數,根據這些訓練數據進行模型參數學習,使得每一條訓練數據的特征向量輸入模型后,模型能夠給出與目標值盡可能接近的預測值(當然,這里也要注意避免前面所提到的過擬合問題),即使得

盡可能小。其中,S是訓練數據集合,ys是機器學習模型對訓練數據s的預測輸出,ts是訓練數據s的目標值,D是某種距離度量函數(如歐氏距離等)。
2.無監督學習
在無監督學習中,每一條訓練數據僅包含特征向量x,而沒有目標值t。聚類(Clustering)是無監督學習的一個重要應用,其自動根據數據之間的相似度,對數據進行分類,從而發掘數據之間的關聯關系(如通過分析社交網站上用戶與用戶之間的關系,將用戶分成不同的群體,以進行相關內容推薦)。除聚類以外,主成分分析這種特征降維方法也采用無監督學習方式。關于聚類和主成分分析,我們會在后面介紹更詳細的信息和具體使用方法。
3.分類
在一個機器學習任務中,如果每一條數據的目標值是離散的,則該任務是一個分類任務。通常用不同的整數代替實際的目標值來進行模型的訓練和應用。例如,假設有若干物體的圖片,每一幅圖片的目標值是狗、貓、輪船、飛機中的一個,則可以將目標值編碼為0、1、2、3,其對應關系是0→狗、1→貓、2→輪船、3→飛機。我們的任務就是設計并訓練模型,使其可以對輸入的圖片產生0~3的整數輸出,而0~3這4個整數分別對應4種不同的物體。
需要注意,對于分類任務,通常也使用One-Hot(獨熱)向量編碼形式表示目標值,One-Hot是指向量中只有一個元素的值為1,其余元素的值均為0。例如,對于前面提到的圖片分類的例子,可以將狗、貓、輪船、飛機這4個目標值分別編碼為(1,0,0,0)、(0,1,0,0)、(0,0,1,0)和(0,0,0,1)。
4.回歸
在一個機器學習任務中,如果每一條數據的目標值是連續的,則該任務是一個回歸任務。例如,假設要對某種產品的價格進行預測,該產品的價格是連續值,因此,該問題是一個回歸問題。需要注意,因為計算機通常用有限的二進制數來表示數據,所以計算機中任何類型的數據實質上都是可數的。通常來說,如果一個任務的目標值在一定精度下可以連續取值,則認為該目標值是連續的。
可見,回歸任務和分類任務的區別就在于目標值是連續的,還是離散的。在實際設計機器學習模型時,很多機器學習模型既可以用于回歸任務,也可以用于分類任務。